







Two years of struggle with brand subdomains. Extreme situations and countermeasures in the mass removal and relocation of 60,000 subdomains and trillions of duplicates. How we did it and what our work entailed can be found in the following lines.
Introduction
Controlled SEOcide is the third part of the series Satan, SEO and Subdomains. In the previous part, subtitled Cancer SEOtherapy, we described the surgical operation of 1000 parametric subdomains generating duplicates. The surgery was successful, but insufficient to completely stop the web contagion. We, therefore, closed the field hospital and set about developing a strategy of mass destruction.
Let’s just quickly remind ourselves of the four main types of Heureka’s subdomains:
- Basic, systemic, and mobile subdomains (
www,m,blog,info) ~20 subdomains. - Category subdomains (
notebooky,mobilni-telefony,elektronika) ~2,500 subdomains. - Brand subdomains (
sony,nikon,apple) ~60,000 subdomains. - Parametric subdomains (
herni-notebook,android-telefony,xbox-360) ~1,000 subdomains.
In this article, we describe the war with brand subdomains. Approximately 60,000 of these were created between 2009 and 2020 and accounted for 92 % of all our subdomains. There are times when we need to throw away our fears and dive headfirst into the fray.
Battlefield Reconnaissance1
Brand subdomains or also brand nooks, for example, looked relatively harmless at first glance. A few pages with an outdated design and links to categories and products. The purpose was obviously to promote internal linking.
We had around 60,000 brands or nooks. 4–8 pages per nook. All in all, we expected a maximum of 500,000 URLs to redirect to a new destination. Specifically to URLs like https://www.heureka.cz/znacky/nike/. So nicely structured under www subdomain and slug /znacky/ ("znacky" in CZ = "brands"). Nothing complicated.

Satellite Imagery
A more detailed survey revealed problems in the "Categories" tab. There, all categories in which any given brand's product was found were listed. And some brands have a really wide range. For example, Nike products are found in more than 150 categories. From all sorts of clothing and footwear to perfumes, and shower gels, to drinking bottles, towels, and soccer balls.
For each such category, there was its own URL in the brand nook, which looked like this https://nike.heureka.cz/batohy/ (hereafter we will refer to it as the "brand category"). The dataset of URLs to redirect grew to 1–2 million URLs.
The really serious problem, however, arose when the brand category page https://nike.heureka.cz/batohy/ looked like our classic category page with everything that goes with it – parameters, sorting, pagination, and so on. All are built on the basis of category and brand filters. In the case of "Nike Backpacks", the URL https://batohy.heureka.cz/f:4168:25445/. The same principle as we described in the previous article about parametric subdomains.
We are not able to accurately determine the amount of redundant and duplicate URLs created in this way. We estimate at least a septillion.2
Brand Battlefield Topography3 v.1
Brand categories were created by duplicating any brand parameter and its surroundings in a category to a new subdomain. As we have already mentioned, this was the same principle we have discussed in detail for parametric sections, only multiplied many times over. For a quick reminder, see the image below. Parametric sections were created by duplicating some filters in a category. For example Backpacks ("batohy" in CZ) + Red ("červené" in CZ) -> cervene-batohy.heureka.cz.

Parametric sections were created manually, usually from one parameter in one category. In contrast, brand categories were created automatically for all brands in all categories. This principle is demonstrated in the image below. For example, from all categories where Nike products were found, the corresponding brand categories were also created in the Nike brand nook (nike.heureka.cz). Backpacks + Nike -> nike.heureka.cz/batohy/. Perfumes + Nike -> nike.heureka.cz/parfemy/.

We had about 2500 categories and 60.000 brands. Brand-parametric duplicates, or brand categories, thus created several hundred thousand.
Canonical Spies
Brand categories had one more specificity. They were supported by a misconfigured canonical in the classic category. Thus, for example, the "Nike Backpacks" page at the URL https://batohy.heureka.cz/f:4168:25445/ contained a canonical that led to the corresponding brand nook at the URL https://nike.heureka.cz/batohy/.
Instead of logically supporting and setting categories with filters as canonical, for some reason duplicates were being supported.
Search engines basically ignored this canonical. Respectively, at least in terms of the common expectation of how a canonical should work. URLs with a brand filter in the categories were indexed to a greater extent and ranked generally better. But there were often wild position changes, with one or the other URL ranking for a while. Just chaos, which is a classic result of duplicates and incorrectly set canonical. Probably the most important negative role of canonical was that it helped the robots to detect constantly new addresses within the brand nooks and supported their indexing.
Unexpected Ambush
We're still not done. Brand nooks and brand categories were among the oldest parts of Heureka and poorly maintained monolithic code. Over the years, there were various bugs that continuously increased the overall URL volume through spider traps.
We encountered various chains of error URLs. For example, when one URL generation modification resulted in URLs like https://nike.heureka.cz/batohy/?o=4//// or https://nike.heureka.cz/batohy/?o=4/////&f=2///////// starting to appear when a misapplied rule on trailing slashes looped and they were gradually added after all question mark parameters until infinity.
Of course, the most serious mistake was when filters for other brands appeared in the brand categories. So, for example, in the brand category "Nike backpacks" it was suddenly possible to filter all other backpack manufacturers. The regular categories were thus dug up in many places. There are about 300 brands in the "Backpacks" category. This means that the category was dug up in almost 300 brand nooks. Brand categories have not only lost all meaning, but more importantly, the number of URLs has again grown by an order of magnitude to at least a nonillion. There was no point in even trying to count anymore.
A Staff Note on the Numbers and Order of Filters in URLs
Now you may be wondering if we're going a bit overboard with the numbers. A nonillion is, after all, 1,000,000,000,000,000,000,000,000,000,000. So 10^30.4
Well, we're not exaggerating. There's one piece of information that hasn't come out yet.
You may have heard that the order of filters and their values in URLs matters. And it matters a lot. We'll demonstrate with a simplified example. We have the URL of the brand category nike.heureka.cz/batohy. There is, for example, a parameter p, which can take values in the range 1–3. So:
- nike.heureka.cz/batohy?p=1
- nike.heureka.cz/batohy?p=2
- nike.heureka.cz/batohy?p=3
- nike.heureka.cz/batohy?p=1,2
- nike.heureka.cz/batohy?p=1,3
- nike.heureka.cz/batohy?p=2,3
- nike.heureka.cz/batohy?p=1,2,3
The example above shows combinations5 of 5 three parameter values, resulting in a total of 7 URLs.
What if, however, the parameter values did not have a fixed position in the URL and could create variations6 and permutations7? Thus:
- nike.heureka.cz/batohy?p=1
- nike.heureka.cz/batohy?p=2
- nike.heureka.cz/batohy?p=3
- nike.heureka.cz/batohy?p=1,2
- nike.heureka.cz/batohy?p=2,1
- nike.heureka.cz/batohy?p=1,3
- nike.heureka.cz/batohy?p=3,1
- nike.heureka.cz/batohy?p=2,3
- nike.heureka.cz/batohy?p=3,2
- nike.heureka.cz/batohy?p=1,2,3
- nike.heureka.cz/batohy?p=1,3,2
- nike.heureka.cz/batohy?p=2,1,3
- nike.heureka.cz/batohy?p=2,3,1
- nike.heureka.cz/batohy?p=3,2,1
- nike.heureka.cz/batohy?p=3,1,2
Suddenly the result is 15 URLs. As you can see in the table below, the numbers, in this case, increase really dramatically.
| Počet možností (filtrů, hodnot filtrů) | Kombinace | Variace / permutace |
| 1 | 2 | 2 |
| 2 | 4 | 5 |
| 3 | 8 | 16 |
| 4 | 16 | 65 |
| 5 | 32 | 326 |
| 6 | 64 | 1957 |
| 7 | 128 | 13 700 |
| 8 | 256 | 109 601 |
| 9 | 512 | 986 410 |
| 10 | 1024 | 9 864 410 |
The creation of variations and permutations of filters and their values was also one of the errors that occurred in the brand categories. We have already mentioned that there are about 300 brands in the Backpacks category among many other filters. The result of the variations and permutations of 300 values of only one filter type, and all times 300 duplicate categories, is an absolutely unimaginable perversion.
Brand Battlefield Topography v.2
So, let's summarize for clarity what all has happened within the brand nooks, or brand categories, and with what conditions we start to make changes.
- In all brand categories, there is an infinite spider trap allowing the generation of an unlimited number of trailing slashes after question mark parameters. (We will describe the solution in a future article.)
- Filters in all brand categories generate variant and permutation spider traps.8 (We will describe the solution in a subsequent article.)
- In brand categories, the restriction to a single brand filter no longer works, and the categories are copied everywhere in their entirety.
At least for a frame of reference, the figure below demonstrates roughly what this looked like.
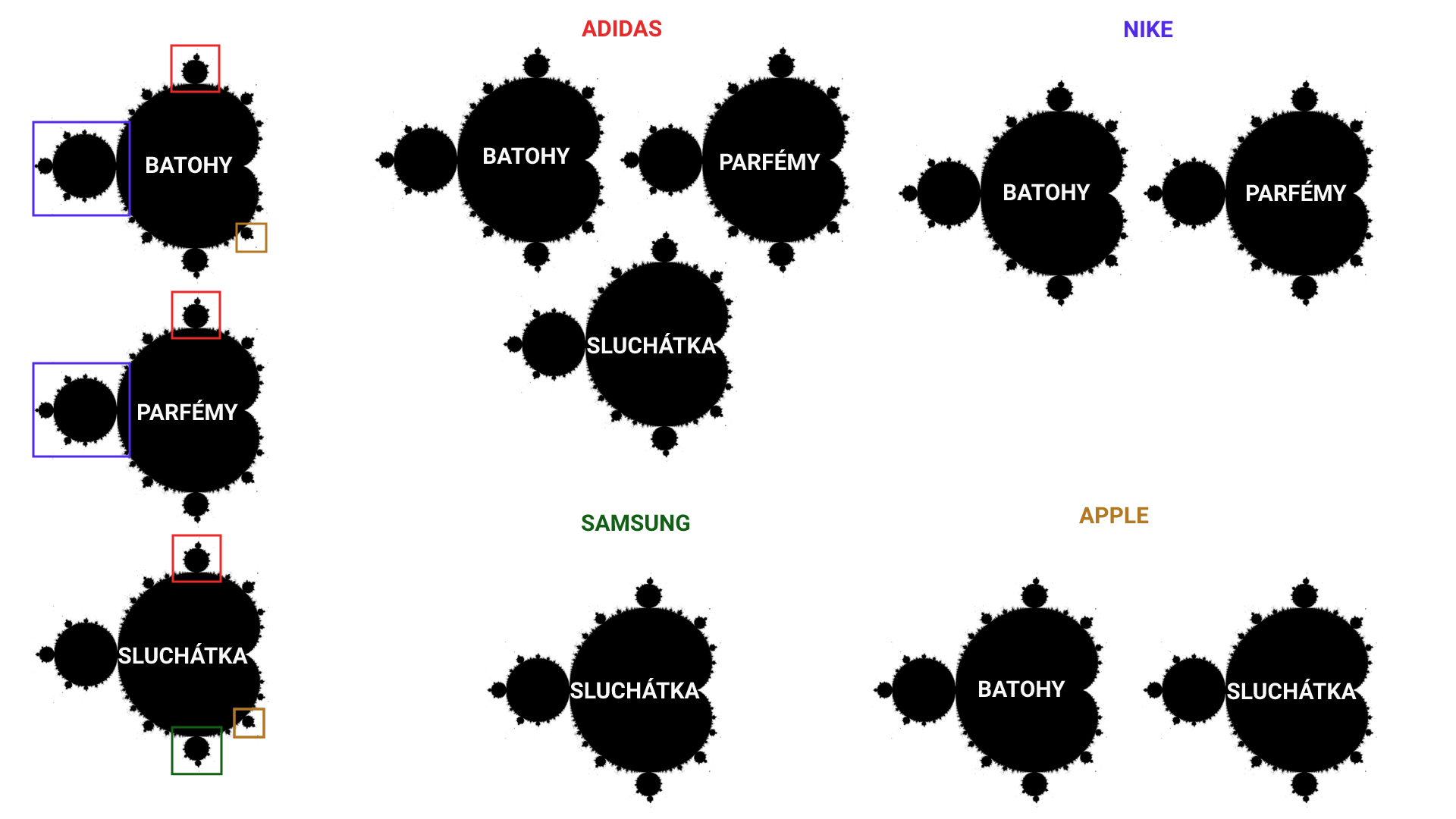
In our first article, we mentioned the concept of the "edge of chaos".9 We have long since crossed that line, and have probably crossed the line of absolute web madness. The fractal images10 actually represents the described state quite accurately.
Brandhattan Project 11
All the duplication around the brand nooks had to go, unconditionally. Capacity-wise, there wasn't much room for some lengthy testing and experimentation, because, at the same time, a very challenging move from a mobile subdomain to a responsive design was also in the pipeline. At least we managed to split the whole event into three phases, plus a quick initial test on a smaller sample.
- Reversing canonical.
- Changing the internal linking.
- Redirection.
Three-part SEOpalm
We edited and redirected the parametric sections in smaller batches. For brand categories, we went all in, albeit with trepidation. In the beginning, we did a quick test on a selected sample of URLs. After a more or less positive reaction from search engine bots and organic, we made all the changes in bulk for all 60,000 brand nooks and started the next phases within a few weeks.
Canonical Ignition
The first step in the process was to "pivot" the canonicals. On the normal category pages, we replaced the wrong canonical with a classic self canonical. In the brand categories, we then led the canonical URL into the category.
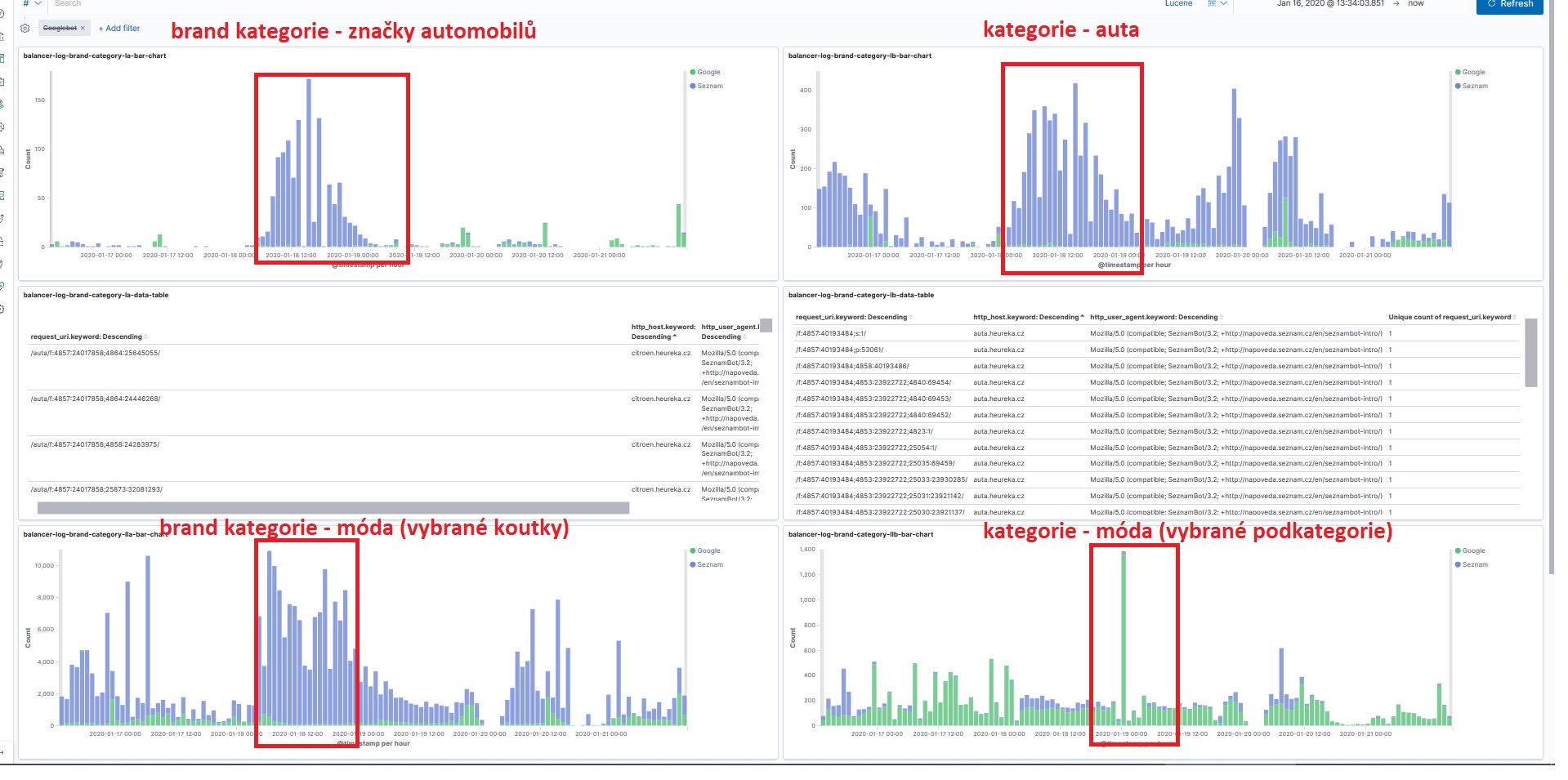
The effect was not staggering. The impact on organic was zero. Probably the most interesting effect we observed during testing was on Seznambot (green in the graph below), which started crawling the given parts of the site quite intensively. For Googlebot, we only saw a spike for the first 1–2 days after the change.

On a larger sample of data and over a longer time frame, we could see a bit later that after the canonical change, the bots started crawling brand categories a bit less and paying a bit more attention to URLs in regular categories. But nothing worth mentioning. It was more of a kind of insurance policy and preparation for the move.
This also confirmed that canonical is not a good way to solve problems. A flawed canonical is a great way to alert the robot to inappropriate URLs and problematic places on the site. However, fixing the canonical will do little to nothing in hindsight. In fact, it's better not to have a canonical at all than to have it wrong.
Link Detonator
The second step was to fix all internal links to brand categories across Heureka.
The data from the access logs in Kibana is interesting. Seznambot (blue) reacted to the change in internal links with short-term increased activity in brand categories (left) and in the regular category with brand filter (right). Googlebot (green) is virtually unresponsive except for one spike.
And again, nothing interesting is happening. No observable impact on organic.
Explosive Component from Enriched Redirect R-301
The third phase finally saw the redirection of brand categories and the brand nooks themselves. New URLs were created for brand nooks. Brand categories were redirected to categories.
Brand nooks: https://nike.heureka.cz/ -> 301 -> https://www.heureka.cz/znacky/nike/
Brand categories: https://nike.heureka.cz/batohy/ -> 301 -> https://batohy.heureka.cz/f:4168:25445/
Interestingly, this move didn't result in any dramatic change either. Brand nooks had so little traffic and apparently quite a little relevance. Flipping the traffic helped increase the conversion rate a bit. But from an organic perspective, we didn't help ourselves in any significant way. A bit disappointing. However, that wasn't the main purpose anyway. The goal was to get rid of subdomains, optimize the crawl budget and remove massive duplicates, which we did.
What was more interesting was that there wasn't any massive crawling of the redirected URLs after the redirect. At least with Googlebot, it was more like it just took a sample of the redirects and simply calculated the rest using some interpolation-like12 mechanism. We will address this issue in the next article.
Notes on the Evaluation of the Effectiveness of the Project
It should be noted that our evaluation had strong shortcomings. In fact, in the course of the described changes, other modifications were continuously implemented, which were related to the testing of the new responsive version of the category. They often hit the same time period. Some led to a complete disruption of our tests and the time pres did not allow us to do a new test. This extremely affected the ability to achieve a better quality evaluation and a more restful sleep. But that's the way it goes with projects like this.
The main conclusion is that the change has been mostly positive.
SEOactive Fallout
The memorable victory took place at the end of June 2020. However, no big event is without consequences. Especially if you weren't consistent enough. It could take weeks or months for the problem to manifest itself.
Dawn of the Mutants
We had to live with the old brand nooks for a while. We were preparing new sitemaps at a similar time, and links to subdomain nooks still existed in the old sitemaps, which couldn't be discarded right away. Three months after the redirects, the sitemaps were still serving as a source of inappropriate URLs. Nothing too serious. But it should have been a subtle harbinger that we weren't just going to get rid of the brand nooks issue.
The Mutants Are Attacking
During Christmas 2020, due to a minor bug in the code, it all came out in full force again. Specifically, the URLs of the new brand nooks www.heureka.cz/znacky/calvin-klein started generating brand categories. For example, https://www.heureka.cz/znacky/calvin-klein/zimni-cepice/f:8582:806096/?f=3.
So many URLs appeared at once that the bots absolutely overwhelmed us with a huge number of requests until the site started to crash. Everything was blocked and eventually redirected.

We dealt with the situation until February 2021. To this day, we still don't know how the bots got to these URLs, as they were not accessible in any natural way that we know of. Theoretically, again, this could have been some phenomenon similar to URL interpolation, where the bot could try different URL patterns and the moment it encountered an active URL, it started crawling.
Mutants Strike Back
In May 2021, functional old brand categories like cser-kiado.heureka.cz/knihy/ or fprice.heureka.cz/podprsenky/ start to appear in reports again. But only in this basic form without filters. There was still a code that generated brand nooks and categories for new brands. And the list of subdomains to redirect was only static.
In June 2021, we are again experiencing problems with brand category URLs containing the order makita.heureka.cz/baterie-k-aku-naradi/?o=2.
We have checked the complete redirect rules and added new address types and new subdomains to the redirects.
Revenge of the Mutants
Another memorable date is June 19, 2021, when we managed to launch the new nooks in a responsive design.
The joy did not last long. One month later, we are still solving the problems described in the previous section. We discovered that new links to subdomains were being generated on our satellite sites that were still being created after the new brand was established. The links from the satellite sites are deleted. But the cause is still not resolved and the original code nooks continue to exist.
Return of the Mutants
The last appearance of subdomain brand nooks was in mid-2022. The part of the code that created them was still functional and new nooks continued to be created on subdomains.
This time, there was a truly complete fix, including an insurance policy that the nooks would not return in any form again. Hopefully.
Half-life
All the described peripeties are proof that redirected URLs cannot be forgotten. Especially when such huge volumes are involved. There is admittedly a half-life13, where the bot gradually visits the redirected URL less and less, everything disappears from the index, backlinks disappear, and so on. However, it takes years for search engines to gradually discard URLs completely and everything really does disappear. We'll keep redirecting for at least 5–10 years. Ideally, forever.
War Reparations14
The work on brand nooks and brand categories took place around 2019–2020. Due to various other issues, it stretched until 2022. At the same time, other big changes were happening. Specifically, the very challenging move from the mobile subdomain, which will be discussed in the next article. Also complete sitemap changes and upgrades, and development of a redirect tool.
Keeping up with everything with just two people was not easy at times. One probably wouldn't have had much chance to stand such an onslaught.
Lesson 1: Plan. Have respect for the work and plan everything precisely. Big changes are not necessarily to be feared. If you plan and execute them correctly, and they actually lead to major improvements to the site, you eliminate a lot of risks.
Lesson 2: Going solo doesn't work. It takes at least two people to do something like this. The work, communication, evaluation, and planning take a huge amount of time. It's easy to get lost in it. Besides, you're always doing several things at the same time – working on evaluating older changes, dealing with plans for the year ahead, and a bunch of ad hoc things that are just happening. One person just can't do that.
Lesson 3: Stress. Another reason why at least two people are better is to spread out the stress and have multiple perspectives on the matter. For big changes, you need to have multiple points of view, to be able to discuss and argue other than yourself. Besides, mutual support will validate your plan, and give you confidence and more peace of mind.
Lesson 4: Details and cause. Solve everything down to the smallest detail. In SEO, often only the consequences of a mistake are addressed. But you must address everything from the cause, to the very core where the problem originates. Otherwise, it will drag you down for years.
Lesson 5: Compromise. Don't fly headlong into something. Don't let yourself be forced into concessions that you are severely uncomfortable with. Some adjustments just absolutely have to be tested, and unpicked. It's not your problem that someone will have extra work to do. That's the problem of the company that expects you to perform in SEO.
Again, like last time, most of the work is in the area of communication and planning. Perfect knowledge of the technicalities is a must and a given. In case you ever find yourself in a situation where you don't know what to do, just make sure you get someone to help you. There's no shame in that. On the contrary.
Cleaning weapons
You may be wondering what tools we used in the course of this work. Here is a brief list.
- Screaming Frog
- Excel
- Google Sheets
- Gephi
- Google Analytics
- Kibana
- Google Search Console
- Marketing Miner
- Collabim
- Valentina Studio
- Redirect Tool – internal custom-made URL redirection tool
Conclusion
Redirecting brand subdomains is the biggest change we have made. We got rid of 92% of the original number of subdomains. The loss of duplicate URLs is in the range of almost untold numbers.
We can now declare the war campaign successful and over. Next in line is the mobile subdomain, which is the subject of the article entitled "One To Rule Them All".
Series on SEO and subdomains
- Satan, SEO, and Subdomains – VOL I. – Chaos Crawling
- Satan, SEO, and Subdomains – VOL II. – Cancer SEOtherapy
- Satan, SEO, and Subdomains – VOL III. – Controlled SEOcide
- Satan, SEO, and Subdomains – VOL IV. – One To Rule MFI
- Satan, SEO, and Subdomains – VOL V. – SEOfirot of the Tree of Life
- Satan, SEO, and Subdomains – VOL VI. – Horsemen of the SEOcalypse
Disclaimer
Approach the text with caution. This article and the entire series are not intended as a guide. The texts do not contain any "universal" truths. Each site represents a unique system with different starting conditions. An individual approach and perfect knowledge of the specific site and the subject matter are required.
The article describes our website. We do not evaluate the general effectiveness of subdomains or directories. Nor do we recommend any specific solution. Again, this is a highly individual matter, influenced by many factors.
Strategies and detailed plans for some of the activities described here have been in the works for over a year. Everything has been discussed, tested, and validated many times. Please keep this in mind when you do similar activities yourself.
Some of the data presented may be inaccurate and purposefully distorted. Specific numbers such as organic traffic stats, revenue, conversions, and the like, we don't plan to leak out for obvious reasons. However, key information such as subdomain counts, URLs, and our practices are presented truthfully without embellishment.
The text may contain advanced concepts and models that are not entirely standard in SEO. The articles are therefore supplemented with footnotes with sources where everything is explained in detail.
Footnotes:
Reconnaissance or research https://en.wikipedia.org/wiki/Reconnaissance. ↩
See note 5 for the article https://www.heurekadevs.com/satan-seo-subdomains-i-chaos. ↩
Topography https://en.wikipedia.org/wiki/Topography. ↩
See note 5 for the article https://www.heurekadevs.com/satan-seo-subdomains-i-chaos. ↩
Combination https://en.wikipedia.org/wiki/Combination. ↩
Variation https://www.mathreference.org/index/page/id/52/lg/en. ↩
Permutation https://en.wikipedia.org/wiki/Permutation. ↩
Spider trap https://en.wikipedia.org/wiki/Spider_trap. ↩
See note 15 for the article https://www.heurekadevs.com/satan-seo-subdomains-i-chaos. ↩
See note 4 for the article https://www.heurekadevs.com/en/satan-seo-subdomains-ii-seotherapy. ↩
Allusion to Manhattan Project https://en.wikipedia.org/wiki/Manhattan_Project. ↩
Interpolation is an imprecise expression of the phenomenon in question, but we could not think of a more appropriate term and simile. https://en.wikipedia.org/wiki/Interpolation. ↩
Half-life https://en.wikipedia.org/wiki/Half-life. ↩
War reparations https://en.wikipedia.org/wiki/War_reparations. ↩
Author
Zdeněk Nešpor
SEO
Technically focused SEO specialist and webmaster.
 Follow us on Twitter
Follow us on Twitter
 Follow us on GitHub
Follow us on GitHub