







A core capability of our team and system is matching e‑shop offers to products in our internal catalogue. Every day, we process millions of offers, each needing to be matched to the correct canonical product. We use traditional ML models for this task, as it's the most cost-effective approach at scale.
Ensuring models perform well before releasing them into production is critical, as releasing models with subpar performance leads to increased business costs.
Validation bottleneck
Before releasing a new model into production, it must pass through a crucial quality gate: validation by Subject Matter Experts (SMEs). While essential, this process is time-consuming and constrained by SME capacity – adding to their existing agenda. The limited number of pairs that can be validated creates a bottleneck, slowing down iteration cycles.
Where do LLMs come into the picture?
Instead of using LLMs for direct matching tasks (which would be cost-prohibitive at our scale), I explored a more suitable application of LLMs in the matching process:
Can LLMs be used as match validators – replicating human judgment to speed up validation workflows?
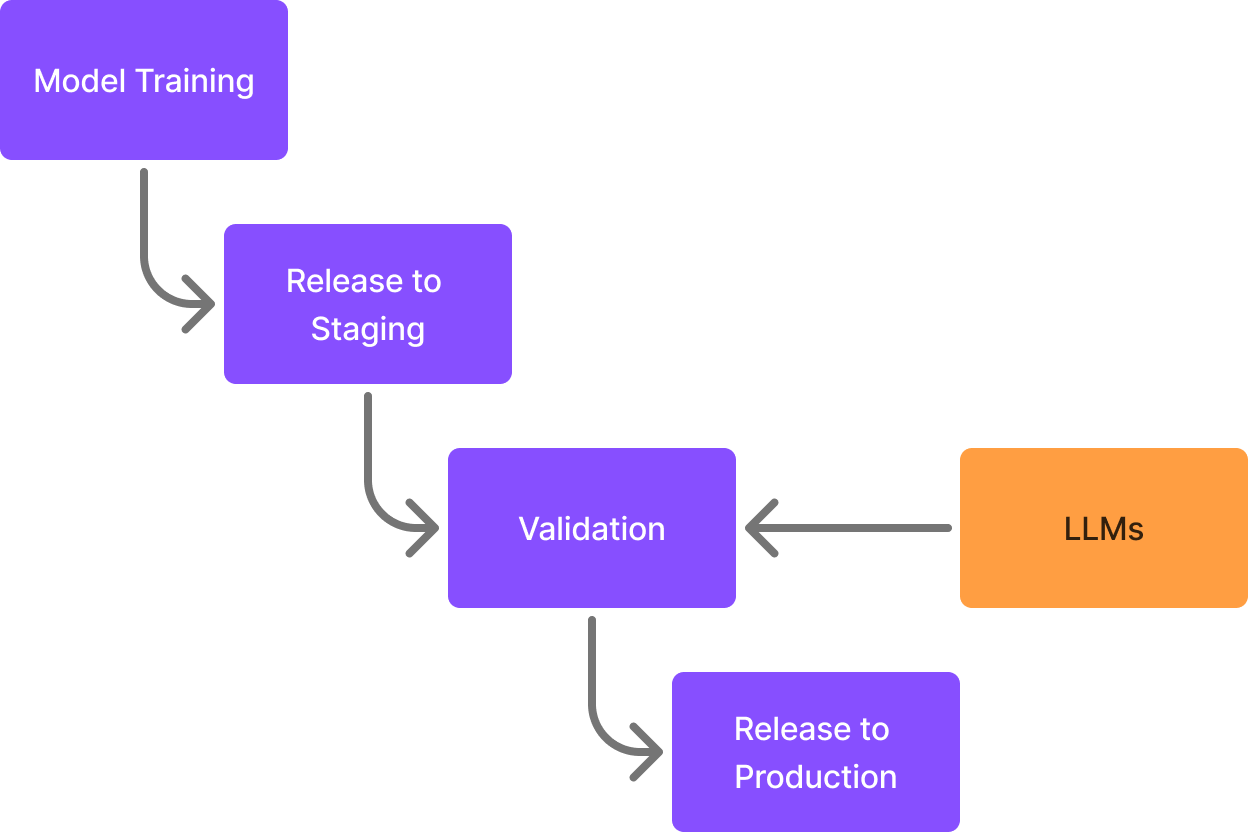
Match validation
UI for match validation
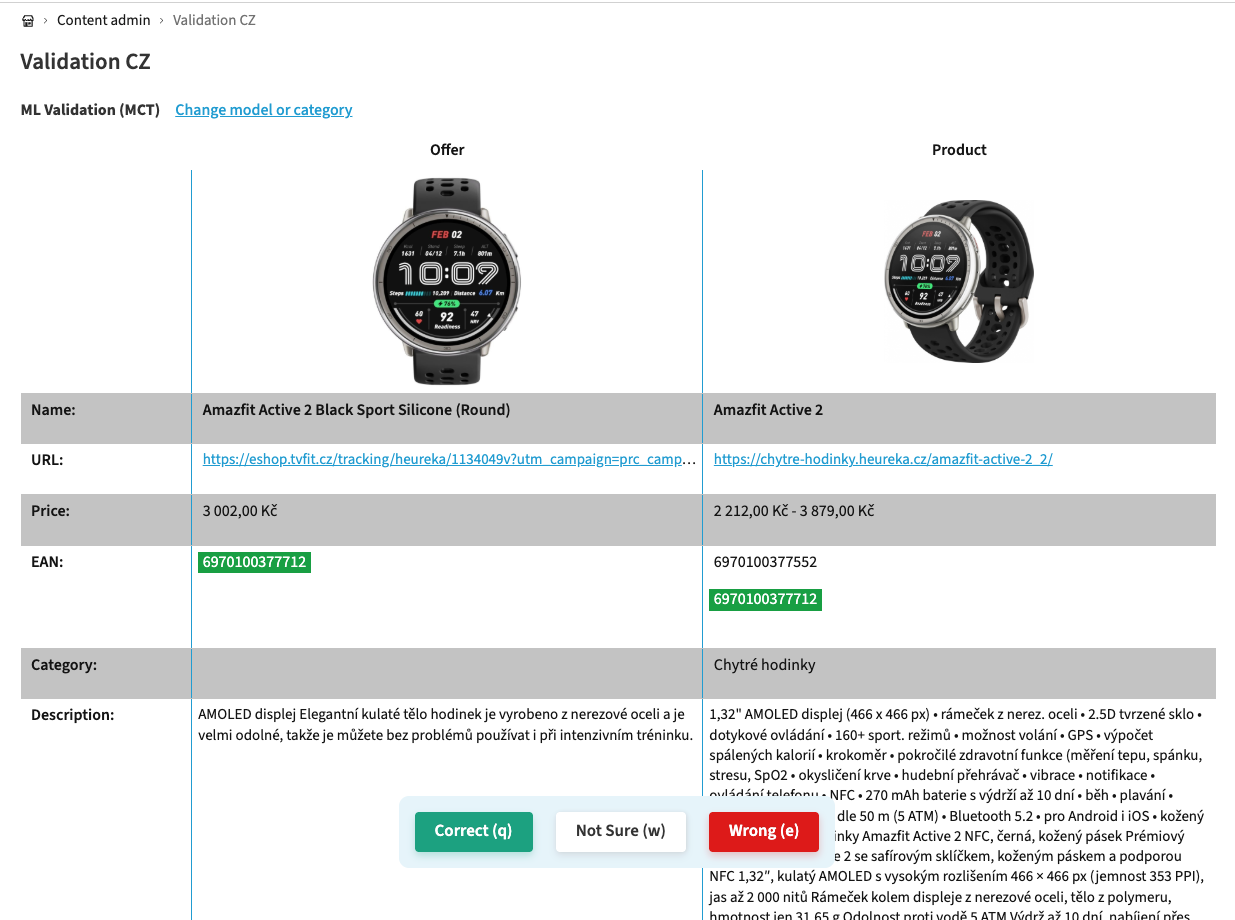
Why is validation a challenge?
- SMEs need to make capacity for validation
- A large sample needs to be validated, considering we have multiple product segments
- Time-consuming – Can take days up to weeks
Goal of using LLMs
Latest LLMs are able to work with multimodal inputs. This allows to feed the LLM with text + images – similar to how a human would validate a match. These two modalities allow to an increase in the information value.
| Hypothesis: LLMs are able to validate matches with the same performance as humans.
Data
Datasets include three types of labels
MATCH→ correct prediction by ML (Model predictedMATCH, SME labeled asMATCH)NOT_MATCH→ incorrect prediction by ML (Model predictedMATCH, SME labeled asNOT_MATCH)UNSURE→ SMEs couldn't determine if the prediction was correct or not
To reduce noise in the data only MATCH and NOT_MATCH will be added to the train and hold-out datasets.
Train dataset
The evaluated sample in the train dataset had approximately 7,000 entries. These evaluations serve as ground truth labels for the LLM.
From the 7,000 validated pairs, I created a balanced sample:
- 168 correct matches –
MATCH - 168 incorrect matches (total number of incorrect matches in the evaluated dataset)
NOT_MATCH - 336 total samples in our evaluation dataset
Hold-out dataset
Hold-out dataset was sampled from a batch of ~15k validated entries.
- 50 correct matches –
MATCH - 50 incorrect matches –
NOT_MATCH
Note: These pairs come from a different batch and do not share the same offer-product pairs. So there’s no data leakage between train and hold-out datasets.
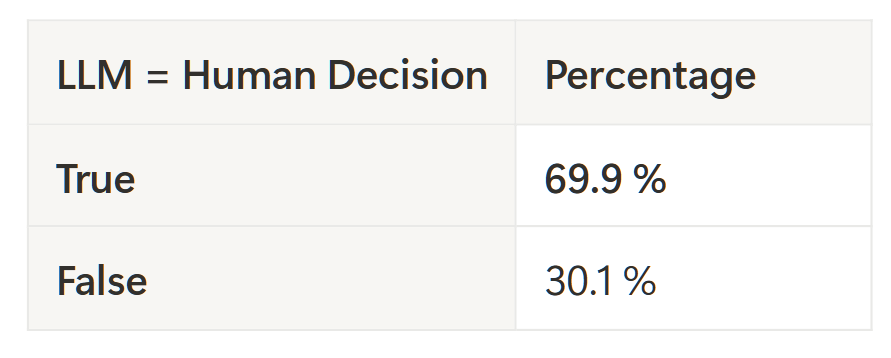
Measured metric – Accuracy
From a machine learning perspective, this task is a binary classification problem.
| Out of all the pairs the LLM called a "MATCH," what proportion did our human SMEs agree with?
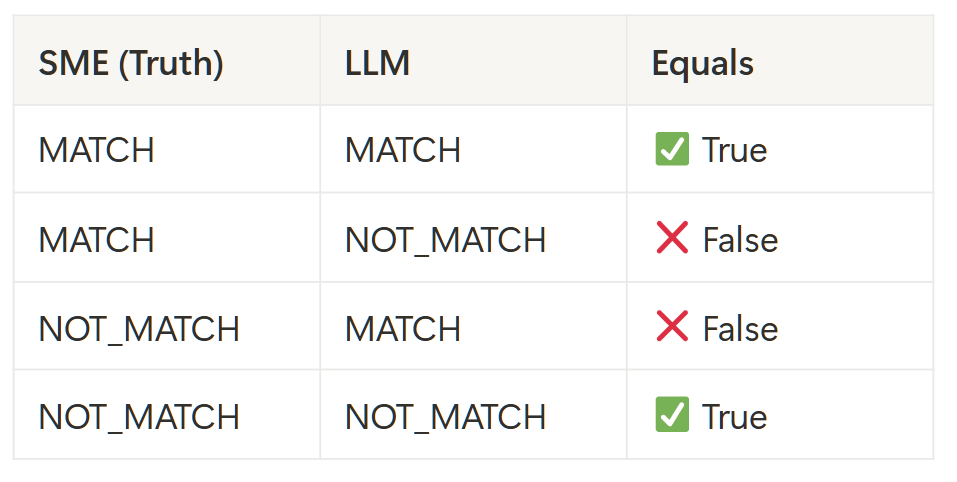
Since the dataset is balanced (50 / 50) I used accuracy as the evaluation metric.
For those interested in the formula:
Accuracy = (True Positives + True Negatives)/ (True Positives + True Negatives + False Positives + False Negatives)
For the example below, the result: Accuracy = 1 + 1 / (1 + 1 + 1 +1) = 0.5
Defining the baselines
Defining a baseline is a standard practice in ML. It represents the simplest possible solution to the problem. The goal is to establish a clear starting point for further interations. A baseline LLM (prompt) will miss some cases by design. This helps to reveal which examples are difficult to classify.
Prompt iterations
After establishing the baseline it’s important to look at the eval dataset. Especially for the case where human_decision!= llm_decision – These cases should guide the formulation of the hypothesis for the improvement of the prompts.
Practical examples from the eval dataset after establishing the baseline:
- LLM was inconsistent in evaluating matches in category of shoes and clothing – in some cases it considered the shoes size as an important attribute for the decision in other cases it did not.
- LLM fixated on the attributes that confirm the match while overlooking the differences that would disprove the match.
- LLM does not have the context at which we operate – there are established internal rules what is considered a match (Cannot blame the LLM in this case – something that needs to be added to the prompt)
Prompt iterations should be linked to Error analysis
LLM Inputs
- Each input to the LLM consisted of
- Offer data
- Product data
- Merged image of an offer and product
Text
class Offer(BaseModel):
offer_name: str
offer_description: str
offer_price: float
class Product(BaseModel):
product_name: str
product_description: str
product_min_price: float
product_max_price: float
product_segment: Optional [str]
class MatchEvaluationPair(BaseModel):
product: Product
offer: Offer
Images

LLM Settings
- LLM: gemini-2.5-flash-preview-04–17
- Temperature: 0.0
Prompts
The Baseline (v0.1)
|🧠 Goal: Establish how far a basic prompt can go.
It’s important to establish a baseline with a simple setup. We need a starting point to which we compare the later iterations of the prompt.
- Simple prompt
SYSTEM_PROMPT = """
You are a product and offer matching expert.
You will be given a product and an offer.
Your task is to determine if the offer matches the product.
"""
- Expected output
## Structured outputs
class Reason(BaseModel):
attribute: str
explanation: str
class MatchEvaluationResult(BaseModel):
decision: Literal["MATCH", "NOT_MATCH"]
reasons: List [Reason]
Results
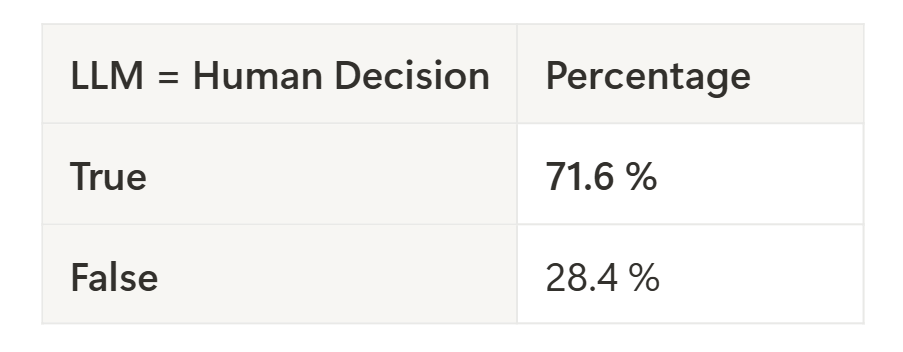
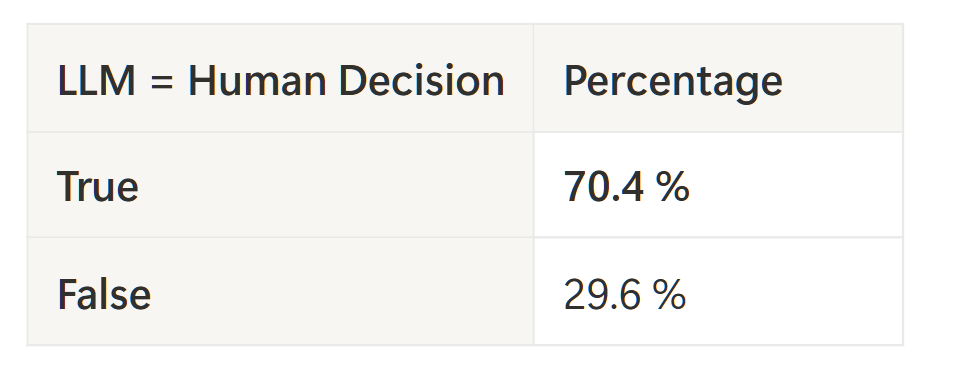
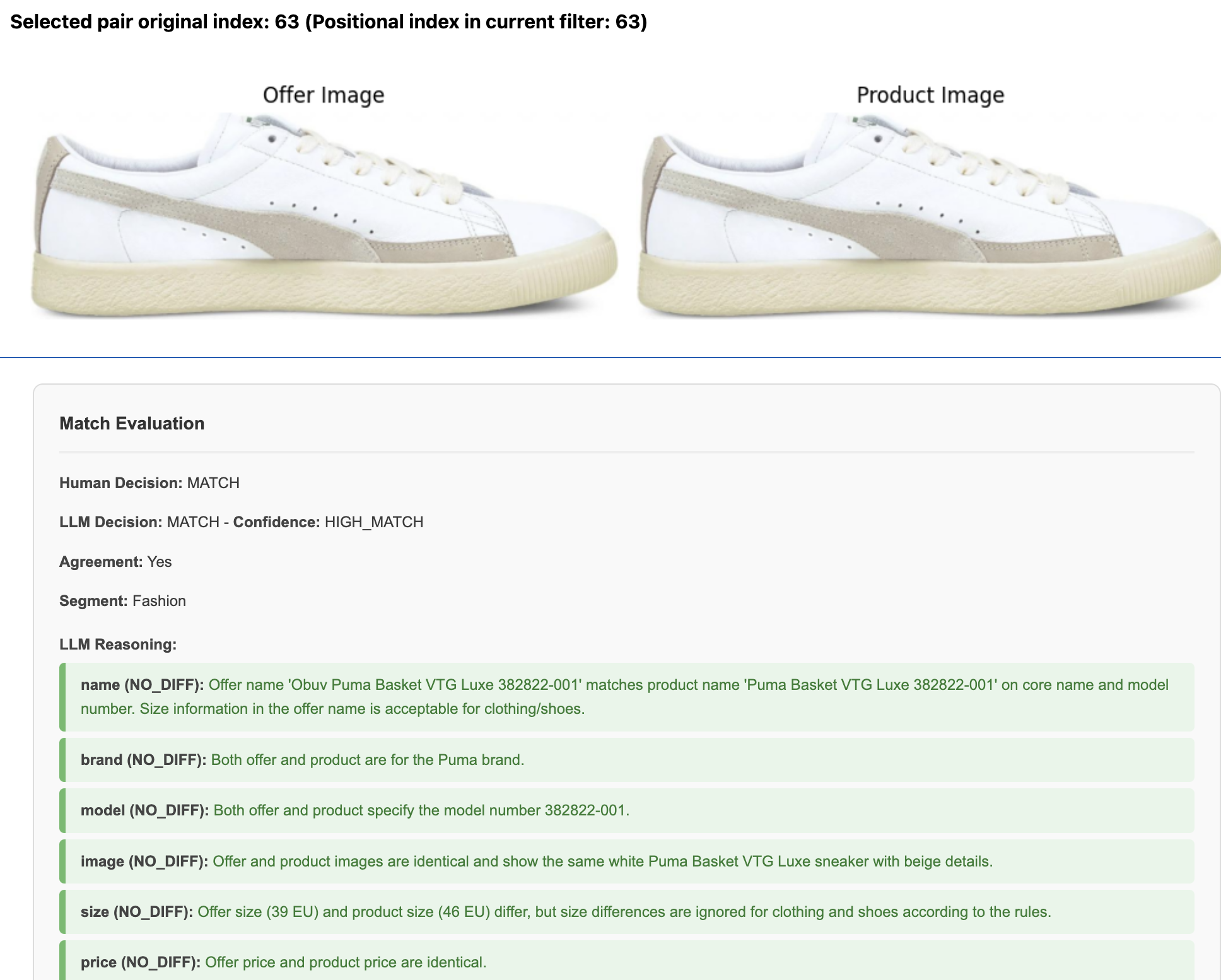
LLM decisions match human decisions in ~71% of cases. Pretty decent for the simple setup.
Once you start to look at the examples, there are a couple of patterns:
- Inconsistency in evaluating shoe and clothing sizes – LLM in some cases considers shoe sizes, in others, not. Pretty clear it needs a rule on how to evaluate such cases.
- LLM also overlooks the differences in the structure of shoes and fixates on the attributes that confirm the match while overlooking the differences that would disprove the match.
Examples
Should be a match as in the shoes & apparel category, size is not considered a difference, and all offers should be matched to one „sizeless“ product.

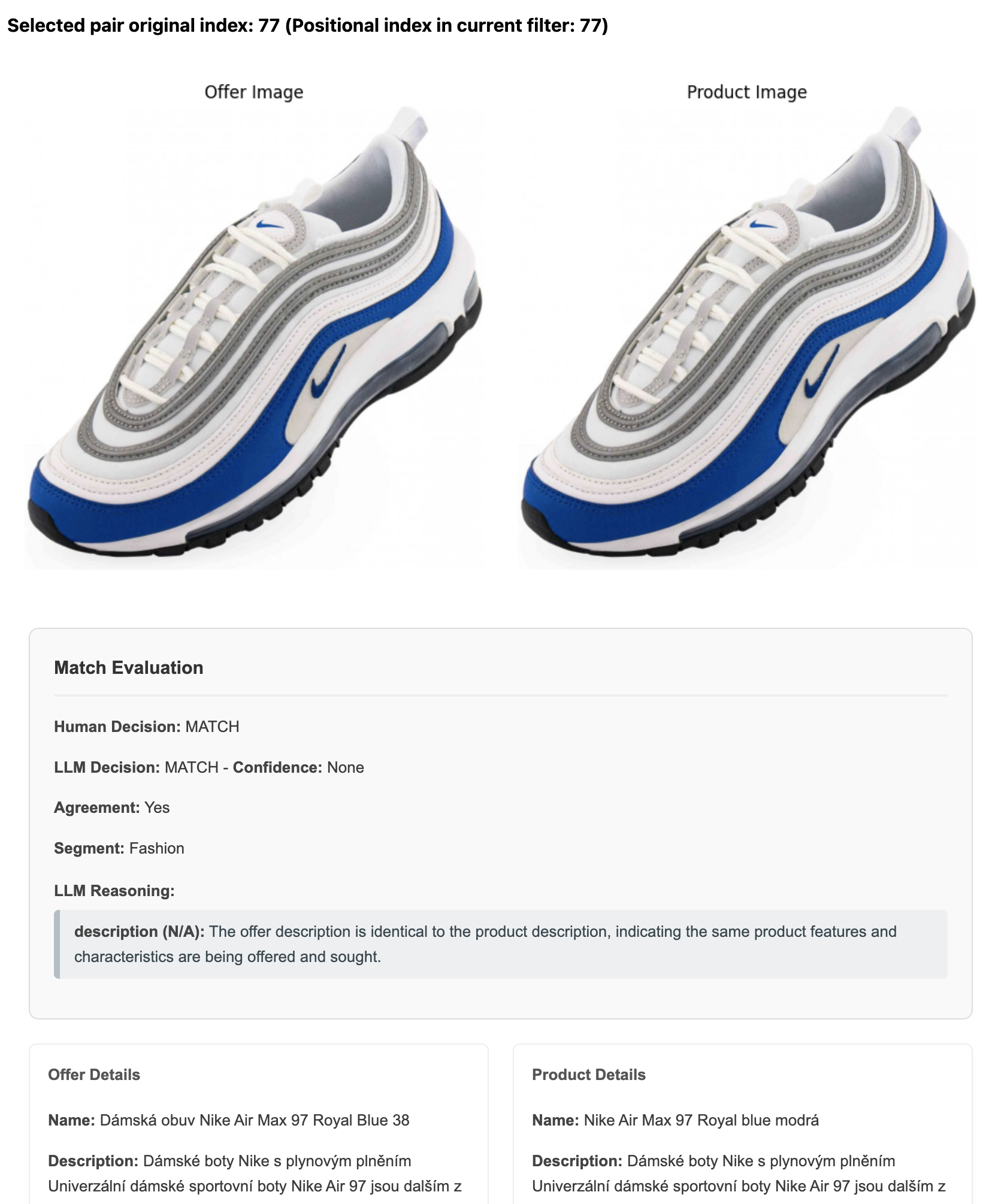
- Inconsistencies in match evaluations – Size is considered for the match evaluation in one case but not the other.
Rule-heavy prompt (v0.2)
|👷 Goal: Embed SME domain knowledge into the prompt.
There are several established rules on how to make a match. To name a couple which were added to the prompt:
- Ignore shoes & clothing sizing
- Product quantities, volumes, and packaging matter – 10 pairs ≠ 9 pairs
- Generic items should not be matched to a branded item
- Product model mismatch →
NOT_MATCH - Signal prioritization: name > image > description
These rules were added to the prompt to achieve consistency in LLM decisions. This prompt is a result of many iterations of analyse-adjust-experiment cycles (and if all prompt changes were tracked, the prompt would be v0.96).
Final token count of prompt v0.2 is ~3600. The token count is high, considering it’s only the system_prompt which does not include product and offer data that needs to be compared.
| High token count → higher costs and increased latency.
The prompt itself increased the consistency of the applied rules. Surprisingly decreasing the tracked metric llm_equals_human_decision.
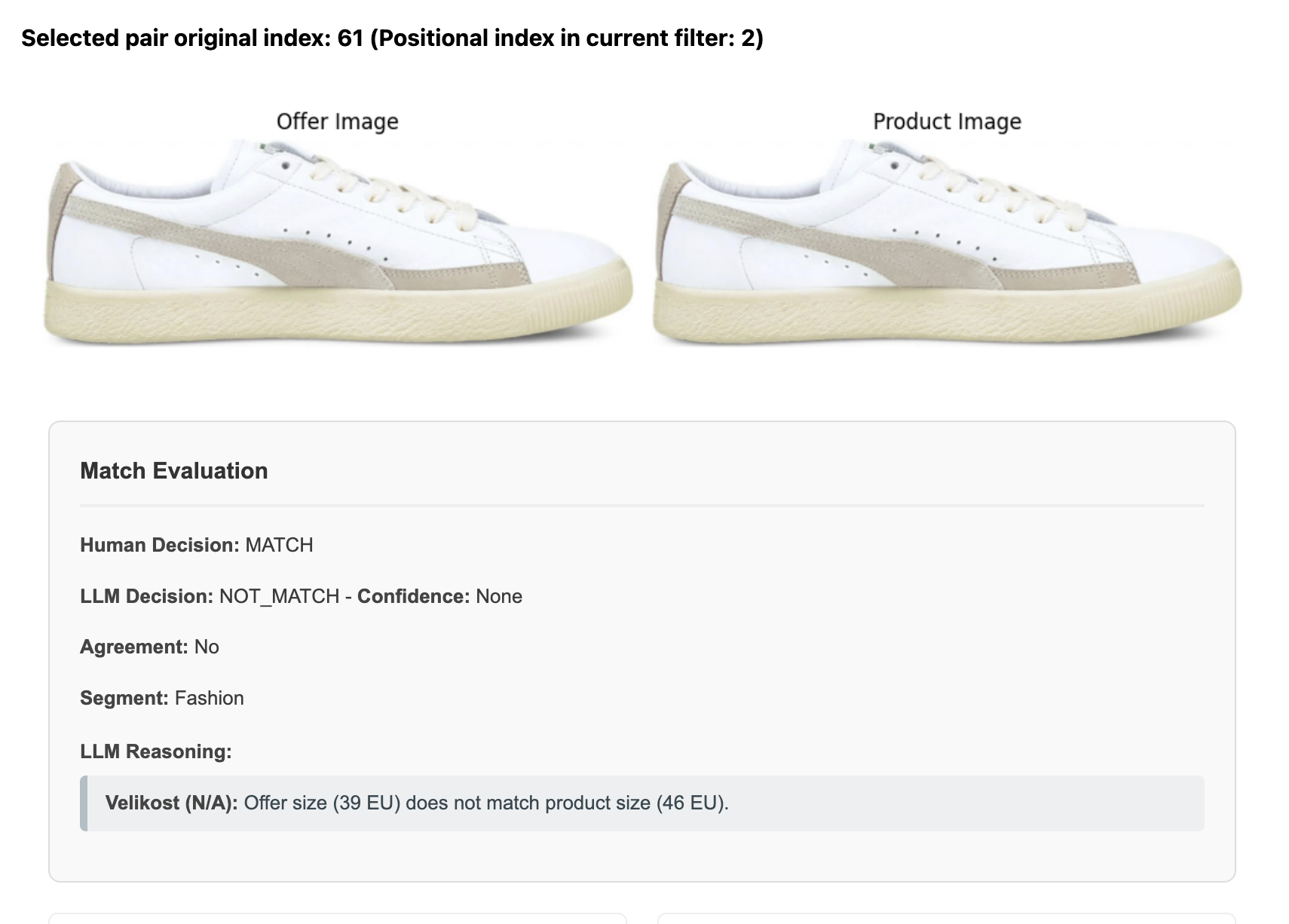
Upon closer look at the errors, there are generally 2 error types I spotted:
- Inconsistent evaluation of generic vs branded is in shoes and clothing, which the LLM evaluates more strictly.
- LLM spotted specs that might have been overlooked by SMEs in the descriptions.
Results
Examples


Prompt diet (v0.3)
|🏁 Retain decision consistency while reducing costs (and latency).
Prompt v0.2 has ~3600 tokens. By restructuring the prompt without losing essential rules and performance. I was able to reduce the token count to ~1400 (~60% decrease in token count).
Prompt v0.3 removes ambiguity which was inherent to the long prompt and many iterations cycles of v0.2.
Results
![]() Examples
Examples

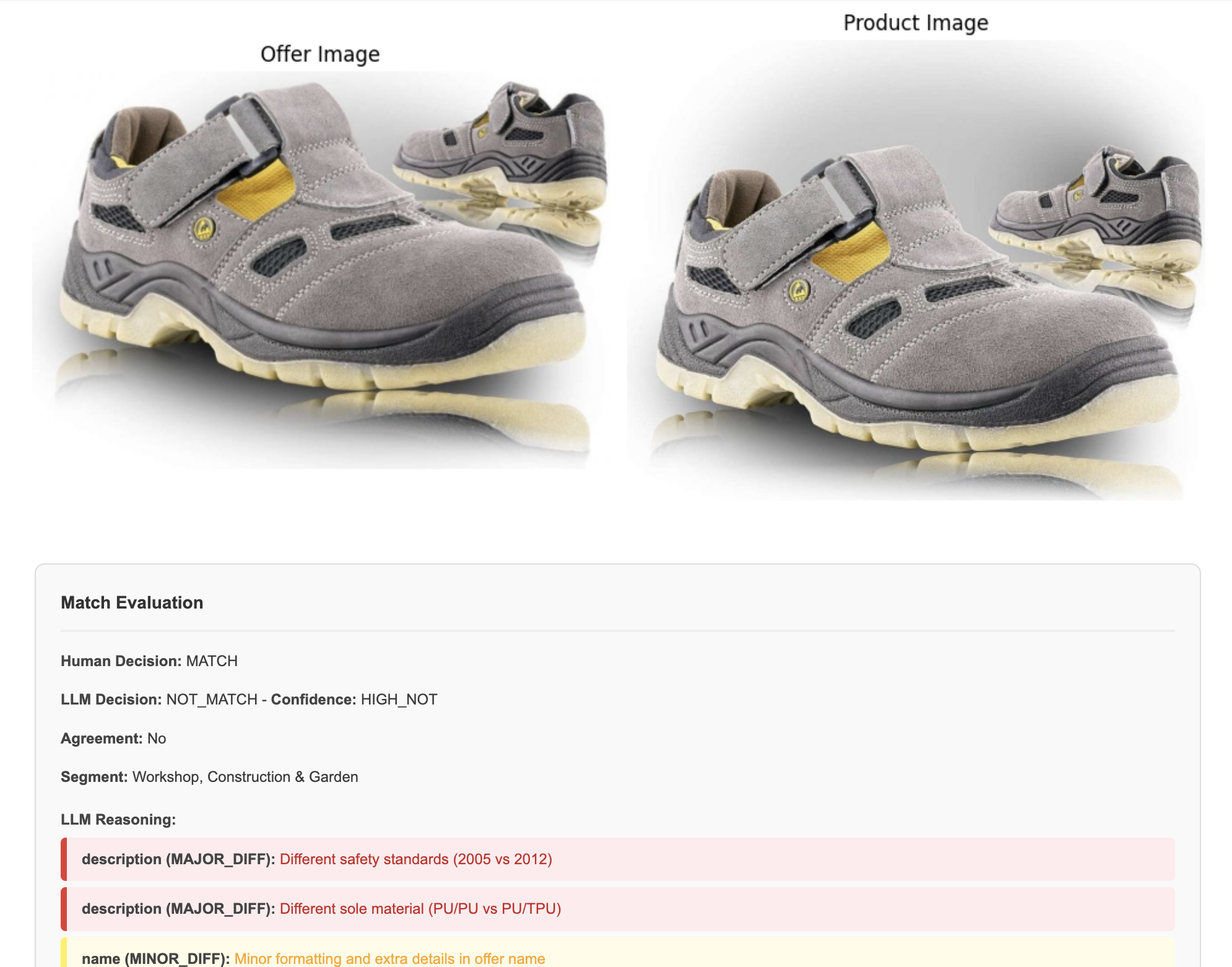
Hold-out set
🎯Verify prompt on ’unseen’ data.
As the last step, I ran prompt v0.3 on 100 samples of unseen data (data that was not used in the prompt engineering process). The results came out better compared to the previous sample.
Results
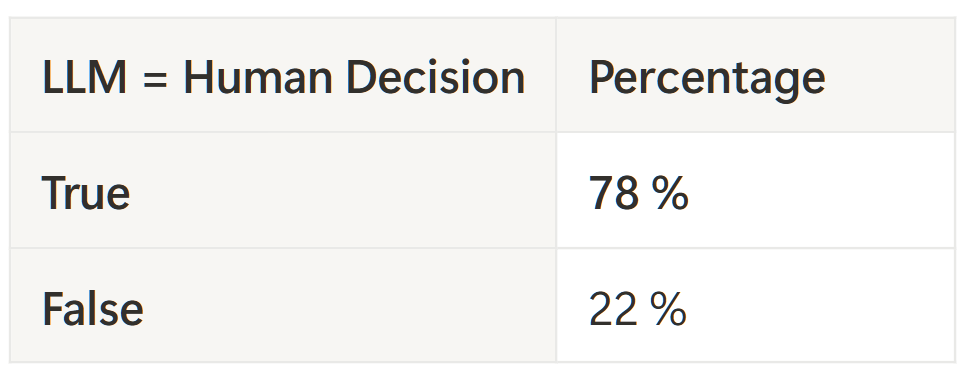
Note: (± 8 percentage point margin of error on 100 samples – there’s a hint of improvement, but still noisy.)
Conclusion on the results
While trying to improve the prompt by introducing rules identified via error analysis. The tracked performance metric is decreasing. See the table below.
| Even though prompt v0.3 scores 78 % on the hold-out, the sample is small. The improvement is not „statistically solid“ yet. A 1 k-pair follow-up test could confirm (or refute) the trend.
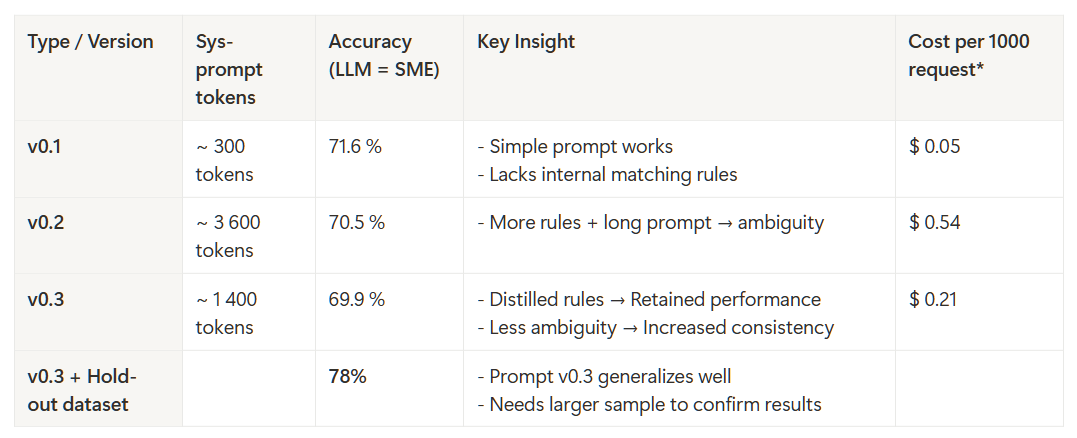
*Token counts refer only to the system prompt; caching is not considered, gemini-2.5-flash
Explanation
- There might be rules or tacit knowledge that are not in the context of LLMs (I did not consult with SMEs – only used the available labeled data).
- LLMs are able to sift through the descriptions more thoroughly and find differences that were not spotted by SMEs. SMEs look for key indicators like a similar image and a matching title. Going back to point 1, maybe a more lenient evaluation could be applied for descriptions (tacit knowledge).
Prompt engineering process via Error Analysis

What’s Error Analysis
| …the single most valuable activity in AI development and consistently the highest-ROI activity. – hamel.dev
In the context of AI/ML – Error analysis is the systematic process of analyzing mistakes a model makes. The goal is to understand why these errors happen, identify patterns, and define targeted improvements.
Process chart
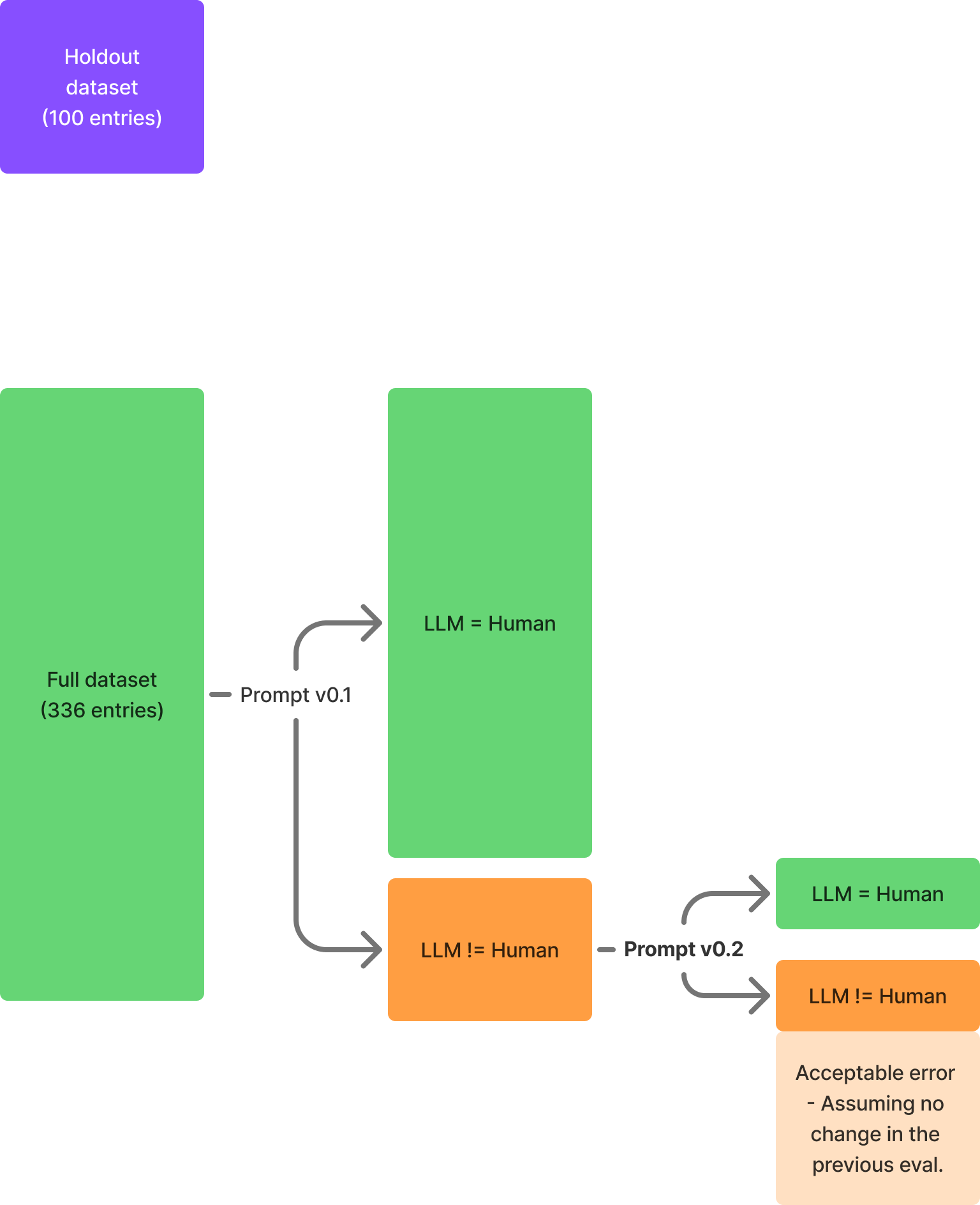
- Define you prompt
- Run the experiment
- Identify the failure modes – „What are the common failure patterns“?
- Formulate a hypothesis and new prompt
- Repeat steps 1–4 until metric hit (or stop because it’s not feasible)
Rerun with the final prompt
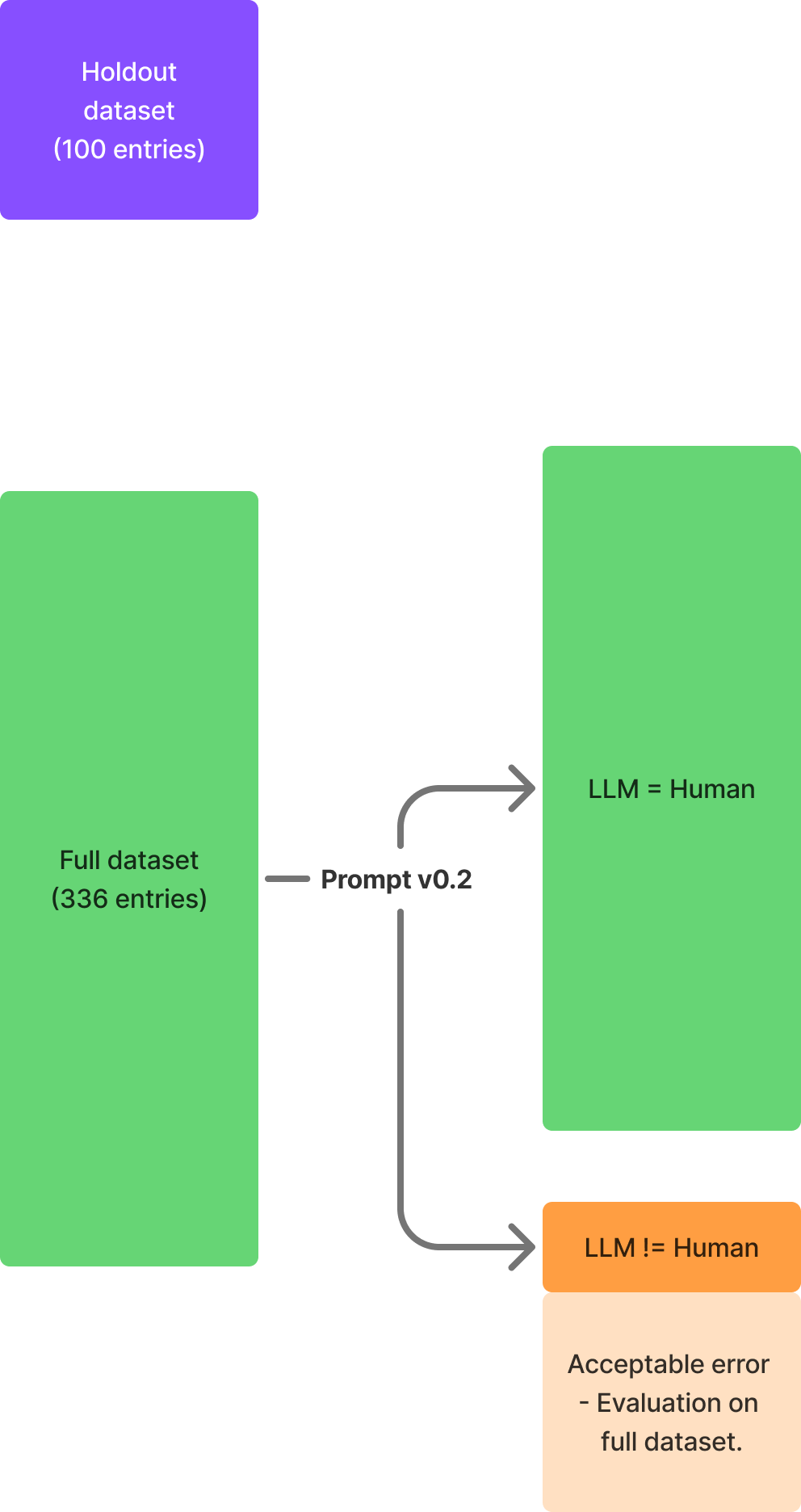
To verify that the changes in the prompt do not affect the overall performance, the final prompt should be evaluated on the full dataset.
Process done?
Prompt engineering is iterative. You can continue indefinitely, chasing marginal gains (or your metric stalls)
Definition of done reached
In this case, you stop the prompt improvement process when you reach the defined success metric. This can be error rates, precisions, etc.
Metric stall
If the metric plateaus and the desired threshold is not met. It’s worth reassessing. It’s worth to:
- Examine the data quality and consistency in labeling
- Validate if the evaluation metric reflects the business metric
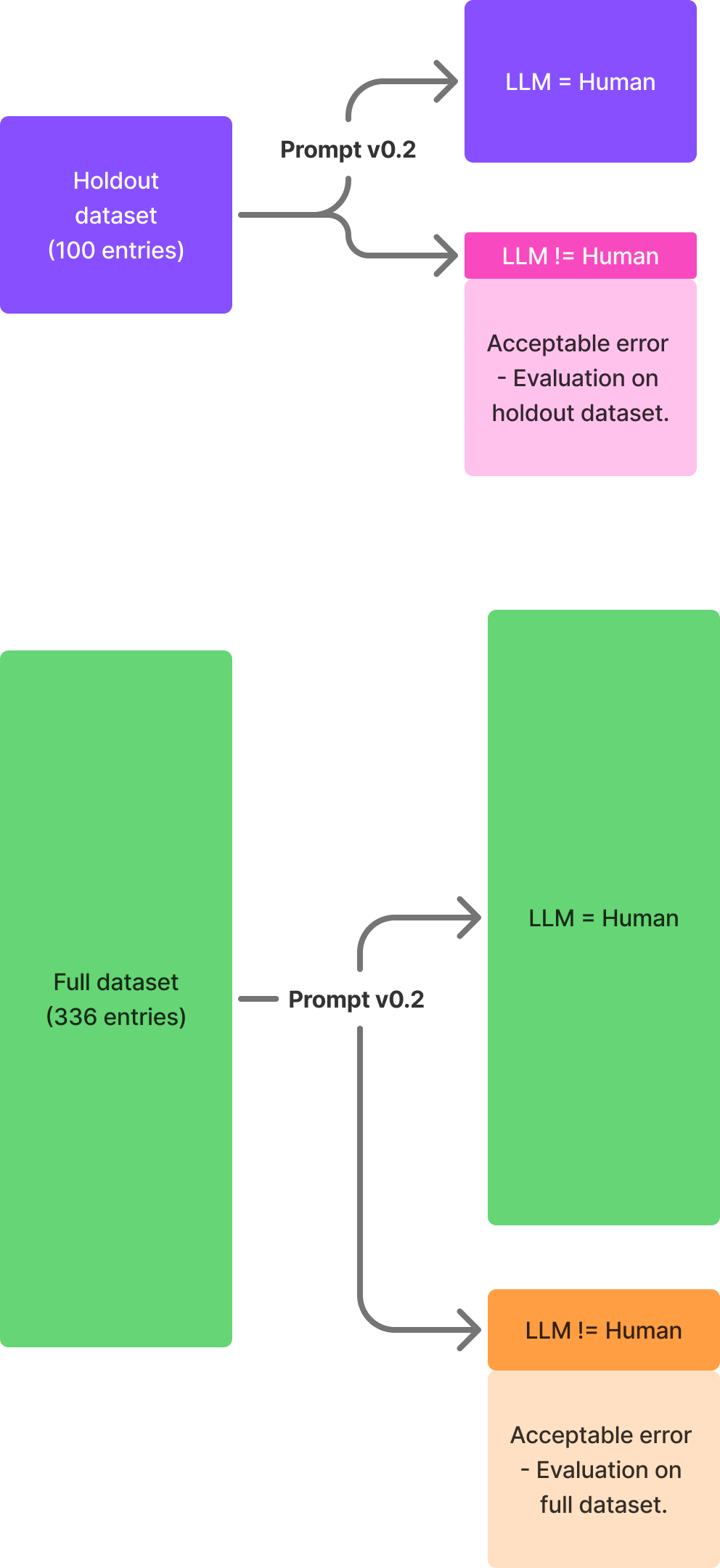
Validation on Hold-out Dataset
Validation on a hold-out dataset acts as a sanity check if the prompt (or model) generalizes beyond the training data. In the context of prompt engineering, it’s possible to introduce „prompt overfitting“ on observed errors in the training data.
LLM Limitations (gemini-2.5-flash)
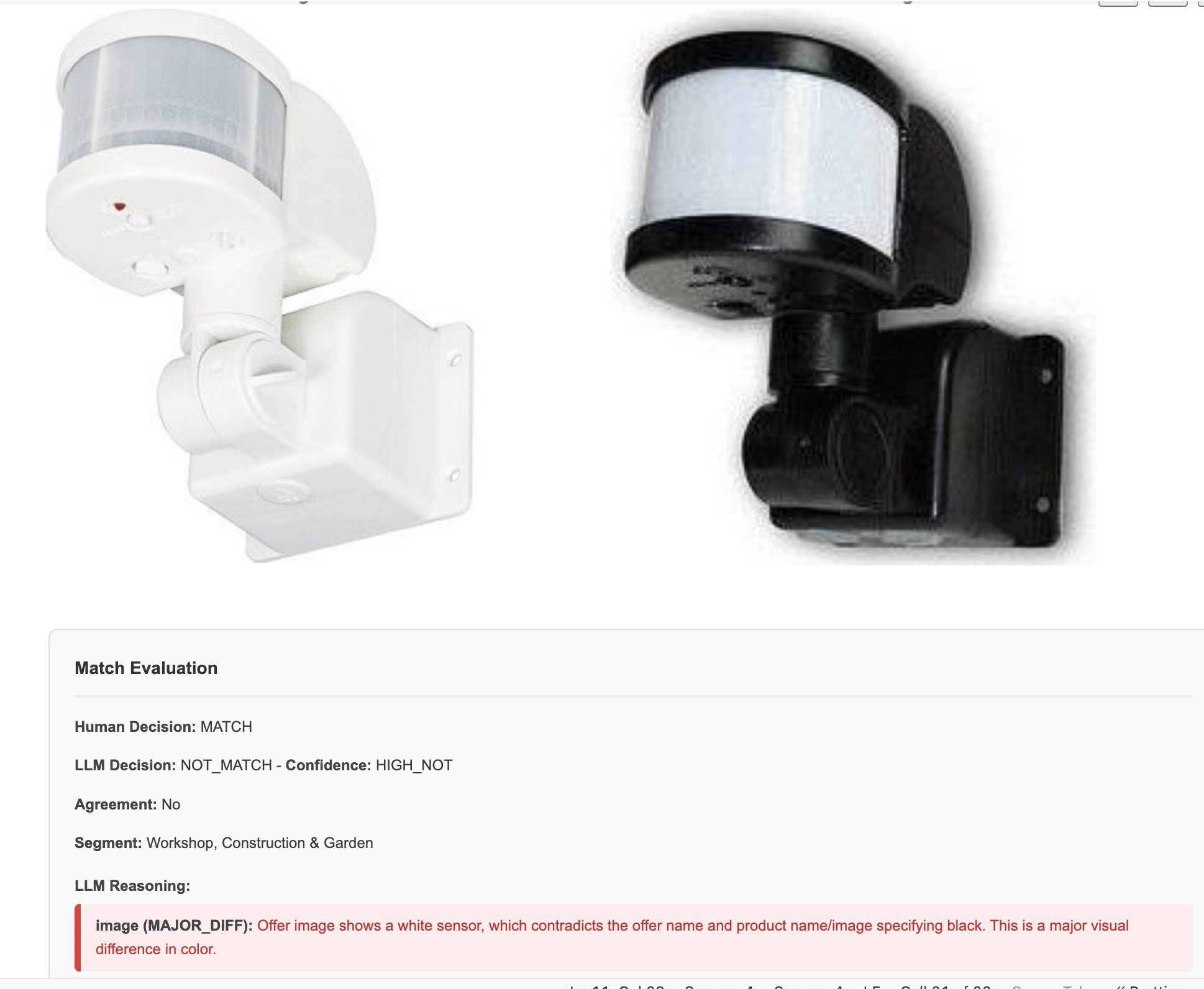
Identifying details in images
- The model failed to spot minor differences like the yellow vs grey tag in the images
- Recognizing different color schemes failed, too
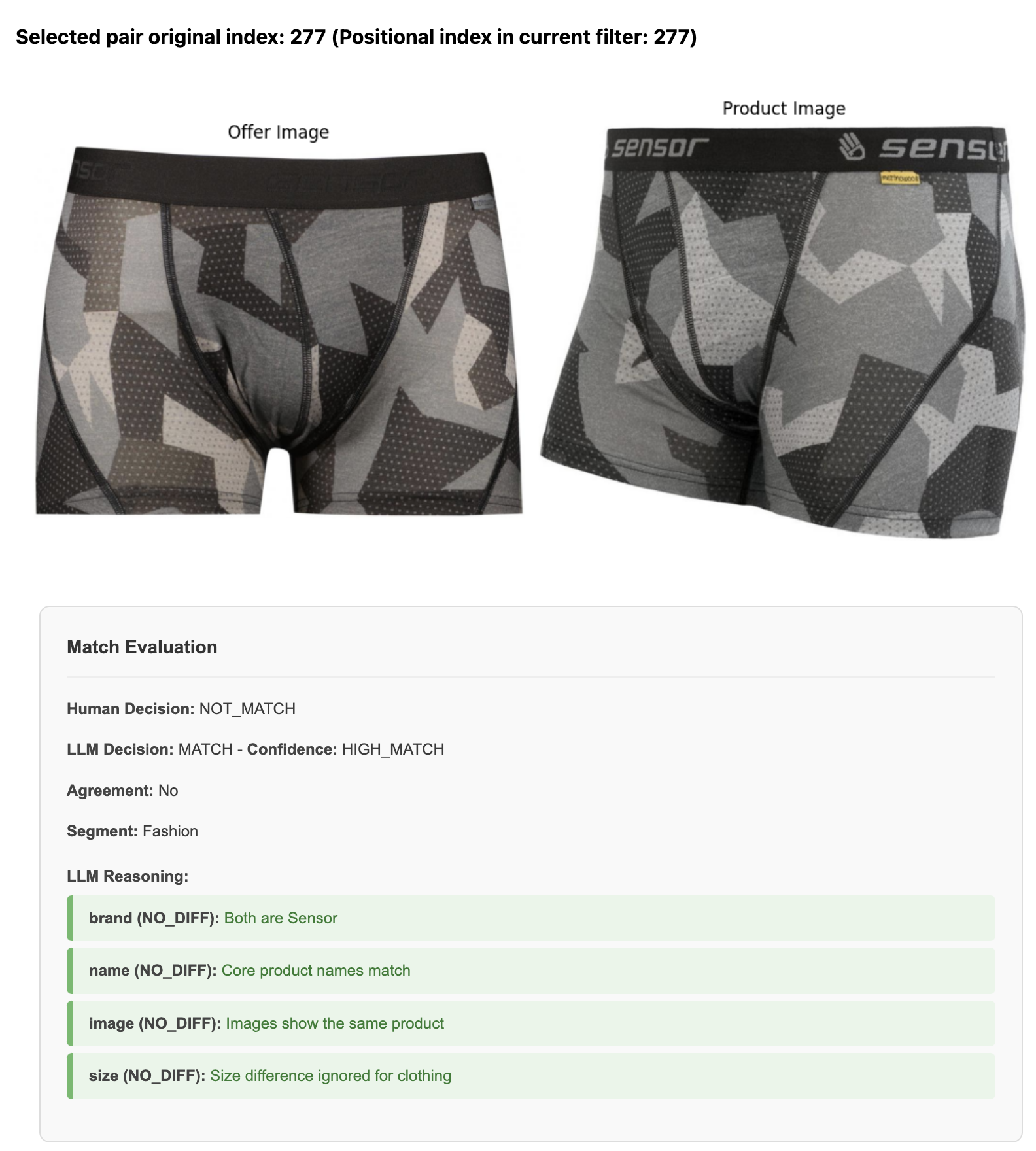
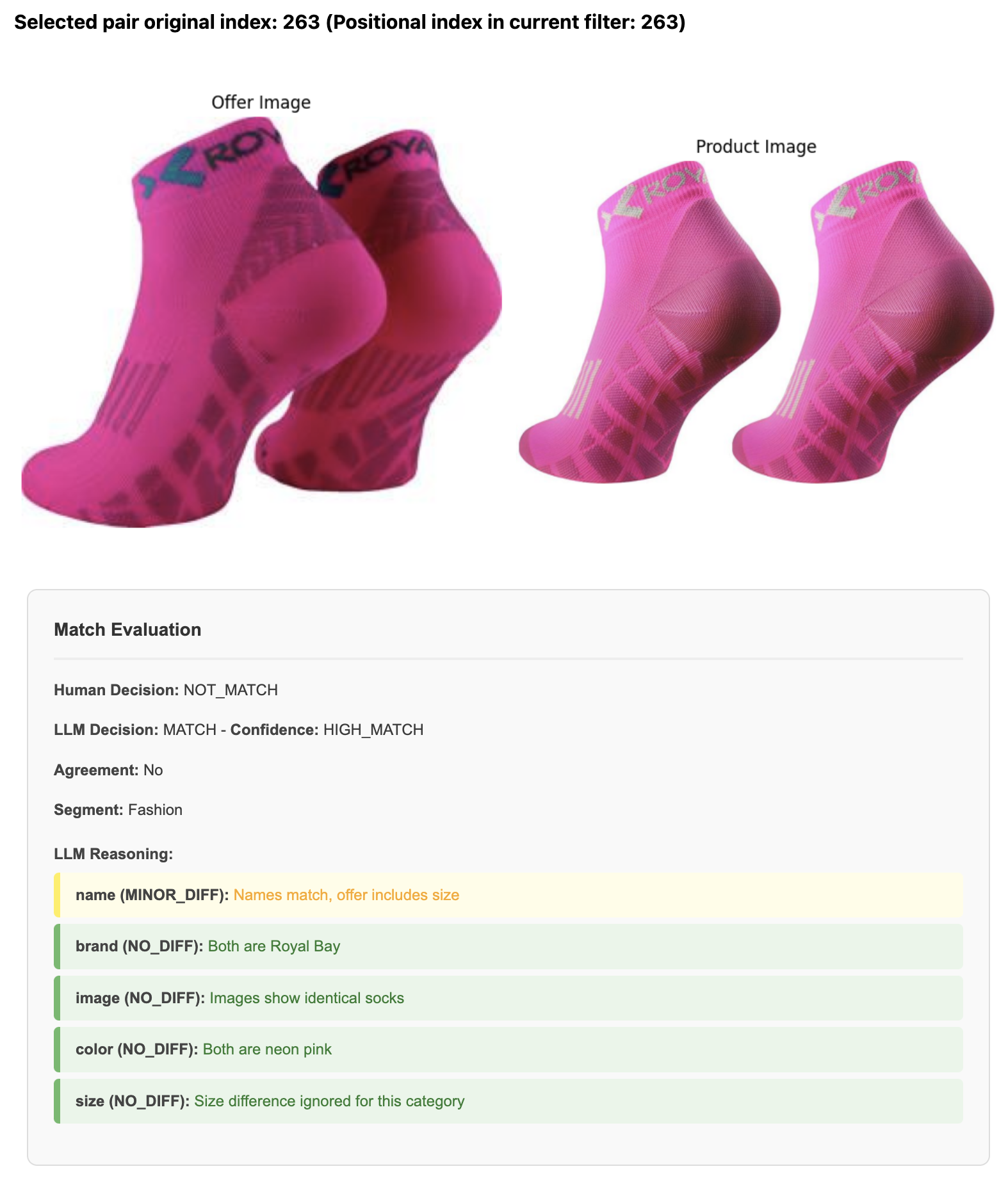
Outcomes
Performance
- Training ~70% agreement between LLM and SME decisions
- Hold-out 78% agreement between LLM and SME decisions
Hypothesis
| LLMs are able to validate matches with the same performance as humans.
- Results look promising, but the hypothesis is not confirmed.
Observations
- LLMs might miss domain-specific context and internal business rules, which can be encoded in further iterations
- In some cases, LLMs were stricter, flagging subtle differences in text while failing on details in images
- LLMs could serve as a first pass validators to reduce workload on high-confidence matches
Takeaways & Learnings
- High-quality datasets are essential. If your evaluation set is noisy or inconsistent, you’ll be playing whack-a-mole with false errors and improvements.
- Start simple. Start with a basic prompt to get strong baseline results. Iterate further.
- Less is more. Once a prompt gets long and layered with rules, it tends to introduce ambiguity. Strong reasoning models (
Gemini 2.5 Pro, o3, Claude 3.7) can help to distill the core logic while reducing the prompt length. - Prototype with larger models. See if the tasks is achievable. You can optimize for costs with smaller models later.
- LLMs can assist with error analysis. They are useful to find common patterns, generate hypothesis and prompt improvements. Human review is still needed – as they try to overfit to the known data.
- Let LLMs explain their decisions. Asking for reasoning speeds up debugging and error analysis. It reveals how the logic was applied.
- Prompt engineering is a tedious process. Hopefully, this is a temporary state. Tools like DSPy.ai are signals that prompt engineering will become part of a higher-level programming abstraction – making today’s manual process obsolete. (Or at least I hope so.)
- Model performance is not a bottleneck. Context embedding is. More rules + long prompt → ambiguity. The added complexity may cause contradiction, vague prioritization of rules, overloaded instructions, which LLMs interpret inconsistently.
Room for improvement
- Systematic error tagging. In this initial phase, error tagging was done manually in notebooks. For larger-scale efforts, a dedicated error analysis tool would provide more structure and scalability.
- Prompt versioning is still messy. Tools like Mlflow, opik, pydantic-evals exist, but setting up infrastructure for this stage felt like overkill.
- Involve SMEs in reviewing LLM decisions and refining prompts. SME can add domain-specific rules and tacit knowledge that are missing from the prompt. Their feedback could help improve model performance.
- Refine evaluation metrics. Accuracy was ok in this case due to the balanced dataset. For real-world scenarios with class imbalance, metrics like precision, recall, or F1 score should be used to better capture performance trade-offs.
What could be leveraged
- LLM assisted training & validation data creation for ML models. They could work as first-pass labelers for high-confidence labels at scale. By filtering high-confidence cases, LLMs can create datasets with minimal human input, while SMEs can focus on edge cases.
- Catalogue quality improvements. During experimentation, I tested a
CONFLICTlabel which is assigned when there’s an inconsistency between the image, title, and description. LLMs picked up these signals reliably, and a dedicated AI system could improve the quality of our catalogue. - Faster validation workflows with LLM pre-screening. LLMs tend to be more conservative. Matches flagged as
MATCHby the LLM can be treated as high confidence. WhileNOT_MATCHare routed to SMEs.
Interested in the prompts I used?
See https://github.com/tkeyo/match-validation-prompts
Author
Tomas leads a Machine Learning Engineering Team at Heureka, focusing on ML/AI systems to match offers with products and drive smarter platform solutions.
 Follow us on Twitter
Follow us on Twitter
 Follow us on GitHub
Follow us on GitHub