Beyond the Prompt: Inside Heureka’s AI-Powered Parameter Extraction Service
Lukáš Vařeka
Development
Sanja Stojanoska
At Heureka, processing offer feeds of varying quality from thousands of merchants is a complex, real-world problem. Large Language Model (LLM) APIs have become a powerful tool for tackling this mess. We introduce Parameter Extraction Service – a microservice powered by OpenAI’s GPT models that automatically extracts structured product data from messy, unstructured offer titles and descriptions. What used to be a manual-only process is now an AI-assisted pipeline built for scale and resilience.
This post provides a behind-the-scenes look at how we designed, built, and evolved the service – from architectural decisions to prompt engineering and error analysis.
The Problem: Parameter Value Extraction
Filters on the left represent parameter name (e. g. Značka – Brand, Objem – Volume) and all possible parameter values (e. g. less than 50ml, 50–74ml for Volume).
Consistent, structured product parameters (e. g. brand, volume, color, etc.) are the backbone of any e‑commerce platform; they power filtering, search, and comparison. The challenge? Our offers come from thousands of sellers in wildly varying, unstructured formats. Consider the following offer name:
"Versace Bright Crystal toaletní voda dámská 90 ml"
Using only the offer name and description, our task is to automatically extract values for the following parameters: Značka (Brand), Určení (Gender/Type), Objem (Volume), and Typ balení (Packaging Type).
The result could look like this (LLM output depicted in red):
Značka: Versace
Určení: dámská
Objem: 90 ml
Typ balení: (not provided)
A quick note on this example: our service focuses on extracting the raw data found in the offer text (e. g., "90 ml"). A different part of our system is then responsible for converting that raw value into the structured, filterable range ("75–96 ml") you see on the front end.
The Solution: A Decoupled Microservice with AI at the Core
The Parameter Extraction Service is a standalone microservice that transforms unstructured offer data into structured parameters using OpenAI’s GPT models. It’s designed with modern software engineering principles – modularity, scalability, testability – and utilizes OpenAPI Batch API.
Architecture Overview
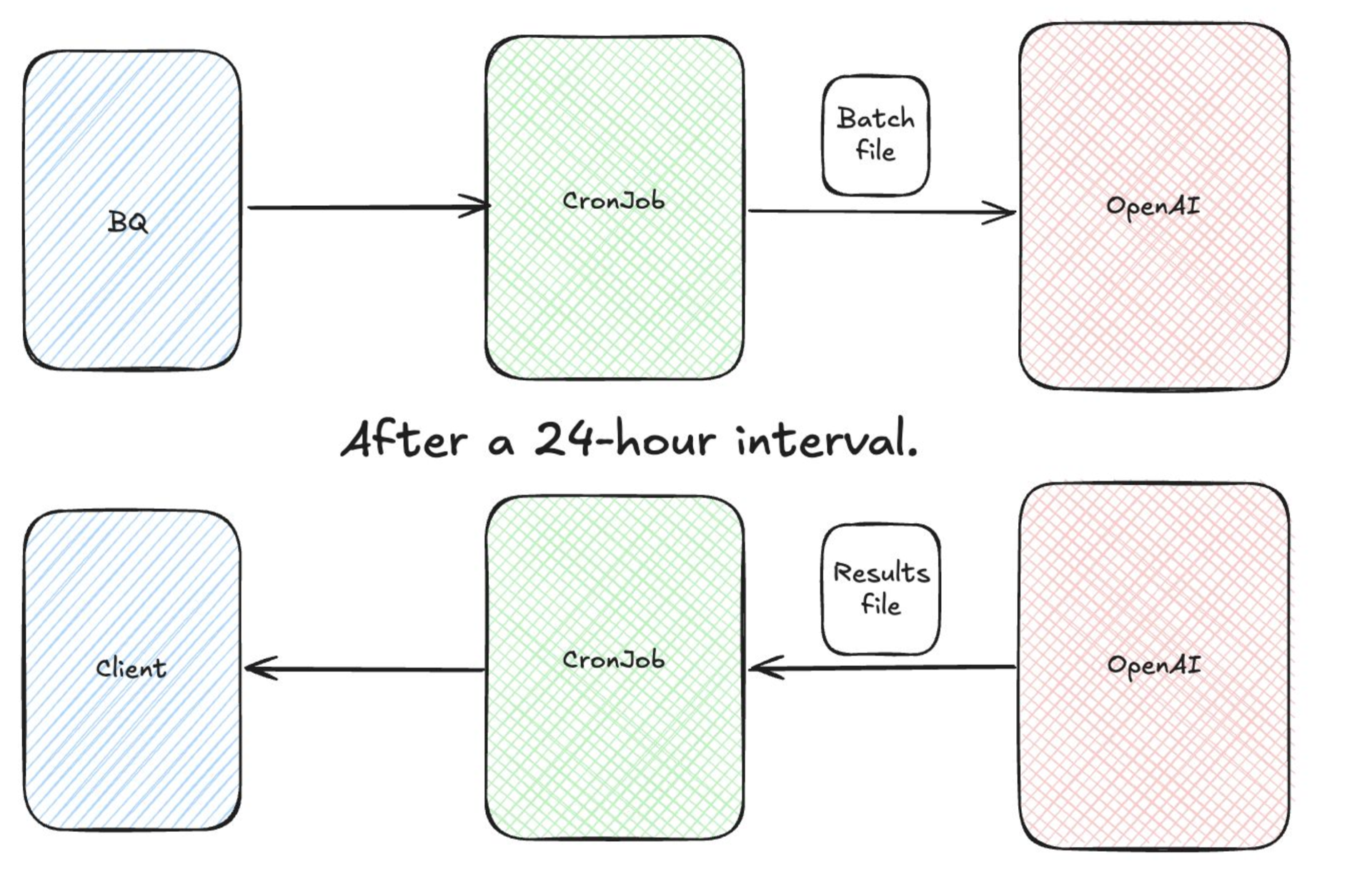
The Parameter Extraction Service operates in two independent, asynchronous stages:
This overview shows two jobs that represent the core of the Parameter Extraction service: the Extraction Job, followed by the Aggregation job.
1. Extraction Job Fetches new or updated product offers from BigQuery (BQ). Offers are buffered and prepared for batch submission to OpenAI’s API.
2. Aggregation Job After the batch is processed, this job downloads the results, and writes the final structured data back into BigQuery and our production systems.
The decoupled nature means each stage can scale independently and fail gracefully.
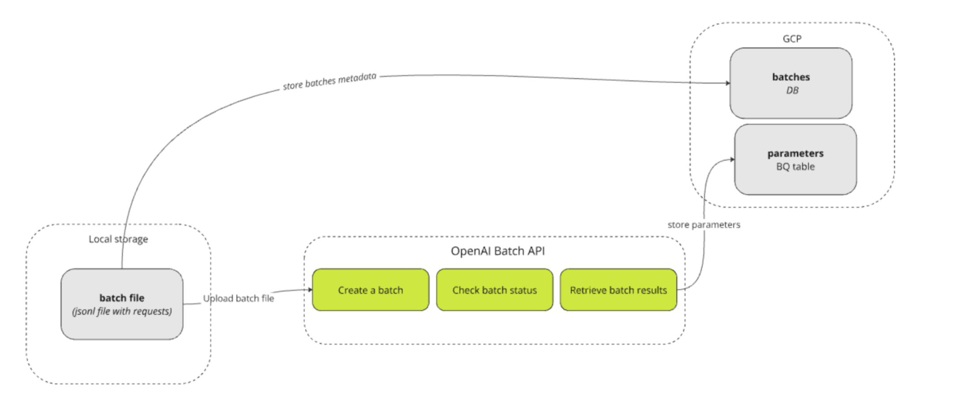
Key Technology: OpenAI's Batch API
The system generates a local JSONL file, sends it to OpenAI for asynchronous processing, and stores both the output and metadata in GCP.
Processing millions of offers one by one through GPT would be prohibitively expensive. Instead, we use OpenAI’s Batch API, which allows us to send thousands of prompts at once in a single JSONL file for asynchronous processing – at roughly half the cost of real-time API calls. The Batch API, which processes prompts within 24 hours, is suitable for our needs because we don't require real-time extraction of parameter values.
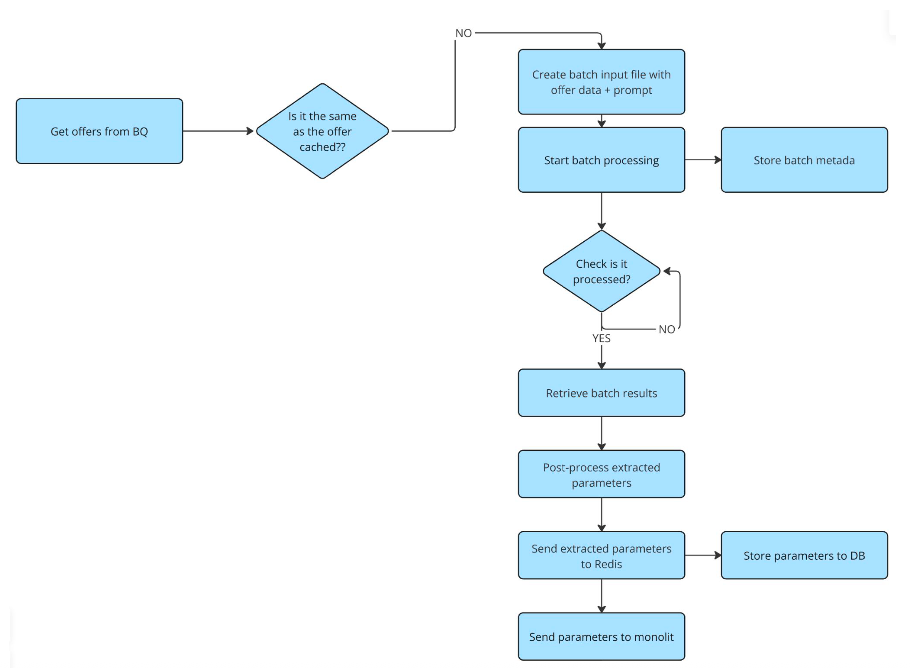
Service Workflow Deep Dive
Parameter Extraction Workflow
Get offers from BR
The pipeline starts by fetching offers from BigQuery.
Check if offer is cached
We have developed a caching mechanism that keeps track of which offers were already processed by our system. More specifically, we create a hash from the offer name and description, which is used for comparison with a newly retrieved offer. If the data hasn't changed, we skip it – saving costs and avoiding redundant API calls.
Create batch file & start processing
Prompts are created from offers and saved in a batch file, which is uploaded to OpenAI’s Batch API for asynchronous processing. Each item in the batch file requires an identifier, in order to combine back together the input offer with the resulting output. Therefore, we provide a custom ID that is a combination of multiple offer identifiers.
Store batch metadata
We record metadata like batch ID and status for observability. Although the Batch API is reliable, the batch processing might fail (e.g statuses like expired: if the batch cannot be completed within the 24h window, failed: if the validation of the data failed, canceled: if a cancellation job has been triggered). Therefore, the metadata is useful in case we need to re-send specific batches for processing.
Poll for completion
The system checks whether the batch has finished.
Retrieve results & post-process
Once ready, extracted parameters are downloaded, cleaned, and normalized.
Store & distribute
Results are saved to Redis and our database, and also forwarded to our monolith for further use.
Prompt Engineering: finding the golden prompt
Crafting good prompts is important for retrieving good results. Current LLM agents require two types of prompts:
System Prompt: Explains the role of the model and expected output schema
User Prompt: Includes the unstructured data to be processed by the LLM, in our case offer’s name and description
Here’s an example:
{
'role': 'system',
'content': """
### CONTEXT ###
Extract and organize product parameters from the provided product name and description.
* You will receive a `name` and sometimes a `description` of a product
* You have to extract a `parameter_value` from the `description` and `name`.
* Format the extracted data in JSON.
* You should complete parameters listed in [### AVAILABLE PARAMETERS ###]
* You should complete parameter values only if they are available; those not available do not include.
* You should fill parameter_values and parameter_names only in Czech.
* For binary values use "ano" if the parameter is available.
* JSON Formatting:
– Format the output as a JSON object with key-value pairs representing each parameter and its value.
– Ensure all keys are consistently named according to the parameter list provided in [### AVAILABLE PARAMETERS ###].
– Use a schema from [### OUTPUT SCHEMA ###]
### RESTRICTION ###
Available parameters: Výrobce, Typ pily, Typ pohonu, Výkon, Příkon, Délka lišty, Hmotnost, Jednoruční, Rychlost řetězu, Otáčky, Ergonomická rukojeť, Třída pily, Hladina hluku, Teleskopické, Max. hloubka řezu, Zdvihový objem, Prořez při 90°, Prořez při 45°, Napětí, Napětí akumulátoru, Kapacita akumulátoru, S bezpečnostní pojistkou, Bezuhlíkové, KickbackStop, Automatické mazání řetězu, V kufru, Rozteč řetězu, S nabíječkou
### OUTPUT SCHEMA ###
{"[parameter_name_1]":"[parameter_value_1]", …, "[parameter_name_n]":"[parameter_value_n]"}
### EXAMPLE ###
## AVAILABLE PARAMETERS ##
vaha, vyska, barva, USB
## EXAMPLE INPUT ##
{"name":"iPhone cerny", "description": "Super cerny iPhone, ktery ma super nizku vahu 450 gramu a vysku 340 mm."}
{"name":"Samsung 41 GB", "description": "Futuristicky Samsung bile barvy. Ma super USB port."}
## EXAMPLE OUTPUT ##
{"vaha":"450 gram", "vyska":"340 mm", "barva":"cerna"}
{"barva":"bila", "USB":"ano"}
"""
}
{
'role': 'user',
'content': '
"name":"Elektrická pila 2000W MAKITA UC4051A",
"description": "PříkonJmenovitý vstupní výkon: 2000 Wnapájecí zdroj: KabelObsah baleníPouzdro na přenášení: NeVlastnostiBarva: ZelenáPopis výrobku: Podmínky používání tříleté záruky DeWalt https://www.dewalt.pl/3/D élka čepele: 40 cmRychlost řetězu: 14,5 m/sRozteč řetězu: 76,2 / 8 mm (3 / 8″)Hmotnost a rozměryHmotnost: 5,6 kg"
'}
The output of an LLM is an unstructured sequence of tokens. Depending on the task this can be good or not. For example, when generating a product description, or review summary, the expected output is not some predefined structure, while for parameter value extraction a specific structure is required. To ensure consistency, we use OpenAI's Structured Output feature, which allows us to define a JSON schema that the model must follow. This removes the need for regex-based post-parsing and minimizes hallucinations. This was a game-changer for us due to the easier output validation. For our use case, the schema is a list of parameters that looks like this:
class Parameter(BaseModel):
"""Schema for the parameters Structure Output."""
model_config = ConfigDict(extra='forbid')
name: str
value: str
class ResponseFormat(BaseModel):
"""Schema for the Batch API structure output."""
model_config = ConfigDict(extra='forbid')
parameters: list [Parameter]
Error Analysis: When the model returns something unexpected
No language model is perfect. To build a truly robust system, we need to understand how and why it makes mistakes. Therefore, we have error analysis as a part of the model evaluation.
We conducted a manual analysis of 1,248 instances where the model's predicted parameter value did not match our ground truth data. Please note, that a match of the model output and the ground truth data is considered an exact same value for a specific parameter. This analysis was crucial for identifying patterns and building an effective post-processing strategy.
Distribution of error types from the total of 1,248. Only 27.3% of miss-matches require manual inspection.
The errors fell into three broad categories:
Missing vs. Found Values (57.3%): The most common mismatch occurred when one value was present, but the other was empty (e. g., None or "n/a"). This often happened when the model correctly identified a value that was missing from our target data, or vice-versa. While difficult to auto-correct, this category highlighted areas where the LLM could find information that our previous systems missed.
Formatting Nulls (15.4%): In some cases, the model returned a None value while the target was the string "n/a". These are semantically identical and can be easily normalized in a post-processing step.
Value Mismatches (27.3%): These were the most interesting cases, where both the prediction and the target had a value, but they differed. After manually inspecting these, we discovered that over 84% could be programmatically corrected because the model's prediction was semantically similar to the target.
We further broke down these "correctable" mismatches into specific patterns:
Detail (27.3%): The model often provided a more detailed, yet correct, value. For example, predicting "keramický povlak obohacený o diamantové mikročástice" (ceramic coating enriched with diamond microparticles) when the target was simply "keramické" (ceramic).
Word Form & Spacing (30.7%): Many errors were simple variations in word form (e. g., "černé" vs "černá") or spacing ("50 g" vs "50g").
Case & Units (21.7%): Simple differences in capitalization (e. g., "Podofo" vs "PODOFO") or unit formatting ("10,1″ vs "10,1 palců") were also common.
String to Boolean (5.9%): In the system prompt we specify that some parameters require a boolean parameter value (e. g."USB": "ano"), while the model extracted a numerical value (e. g."USB": "2″). These predictions can be corrected by trivially converting string to boolean, e. g. by regexes. Examples: „2x“ → „ano“, „bez displeje“ → „ne“.
This deep dive into the model's errors was invaluable. It proved that many "mistakes" were actually just formatting inconsistencies. This gave us a clear roadmap for our post-processing logic, allowing us to build rules that correct these predictable variations and significantly improve the final quality of the extracted data.
What We've Learned and Achieved
Having structured parameters that help users find desired products, and potentially make a purchase brings significant value for the company. The solution we implemented replaced a lengthy manual process with new AI powered solution. Launching the first version of the Parameter Extraction Service has proven this approach successful, with the most immediate impact being a 15% increase in parameter coverage across our product offers.
Beyond the metrics, this project demonstrates several key principles for building with LLMs at scale:
Start with experiments and proof-of-concept: there are a lot of options out there, many models, frameworks, APIs that do similar job. Before building the whole infrastructure, it is important to experiment with the narrow selection of models and show that it can be a solution to your problem.
Optimize the prompt size, while keeping it rich with information: From our experience we can state that (few-shot) prompts that contain examples of the expected output outperform the simple prompt that only asks the model to „do something“. But be aware of the costs! GPT tokenizer is a useful tool we used to estimate the costs. Also note that languages contain diacritics in their alphabet are usually split into more tokens (e. g. iPhone černá = 6 tokens, while iPhone cerna = 5)
Keep track of batch statuses: when using OpenAI Batch API, it is possible for a batch processing job to fail. Having batch statuses you can easily identify which batch failed and process it again (instead of retrying the job with lots of batches twice).
Set meaningful custom_id: This unique custom_id value is required to be able to reference results after completion, simply said matching each request with the response from the API. In our case it also holds information about the version of the offer used for extraction (by providing a hash of the offer name and description).
What's Next? Key Challenges for Production AI
Launching a successful AI powered service is just the beginning. For us, the next steps for the Parameter Extraction Service are focused on measurement and refinement. Our plans align with the key challenges we believe any team will face when moving from a proof-of-concept to a production-grade AI system:
Building an LLM Evaluation Framework: A manual error analysis is great for getting started, but it doesn't scale. The critical next step for any project is to build an automated evaluation framework. This would allow us to track model performance over time, detect regressions, and prove the value of any changes, whether it’s a new prompt or an updated model.
Implementing a Post-Processing Service: Our analysis proved that a significant number of "errors" are actually just formatting inconsistencies. Raw LLM output is rarely clean enough for production. A dedicated post-processing layer that normalizes casing, spacing, and data types is essential for transforming "almost correct" output into high-quality, reliable data.
Prompting and models: There are many novelties in the generative world, better, more specialized models that might boost further the LLM output quality.
At Heureka we are building a structured product catalogue, and this service is one step into this direction. By continuing to measure, refine, and build upon this foundation, we can transform even more messy text into trusted, high-quality data.











 Follow us on Twitter
Follow us on Twitter
 Follow us on GitHub
Follow us on GitHub