In recent years, Heureka has evolved technologically – we can mention the international OnePlatform, migration to the cloud, or transition from monolith to microservices architecture. And thus, the number of autonomous development teams has increased as well. And so, the need for immediate response to ongoing incidents within each team has grown significantly – either by fixing the problem or escalating it to the team(s) who can fix it.
But who to contact with the escalation, when the team doesn't have an On-Call duty? 🙂 Therefore, our DevOps workgroup decided, that any team that has any business critical (micro)service running in the cloud must start with On-Calls.
How we started with On-Call in the Search team
Our Search team was one of the first teams to migrate services to the cloud, therefore one of the first to begin with On-Calls. So we started to create the On-Call alerting rules from scratch, according to our experience from former problems or bugs that have occurred in our services.
On the one hand, we knew that if we detect the problem early, the fix would usually take just a few minutes (and if we leave them unresolved over the weekend, we fix them all day on Monday 😀). On the other hand, we didn't want to be disturbed outside of business hours again and again unless the issue was really severe.
Considering that, we originally defined dozens of rules, based on various inputs, e. g.:
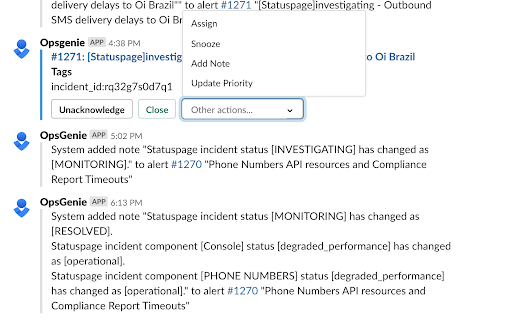
Opsgenie is generally used as an alert/incident management platform in Heureka, but not exclusively. Some systems send alerts directly to Slack, or others via email.
As a next step, for the needs of our team, we added integration to Opsgenie to all source monitoring systems. And then started sending all alerts strictly to Opsgenie, which serves for Search team as the only central notification and escalation platform – and no other channels are allowed.
But in practice there were flaws…
Alert fatigue
Due to the huge number of rules covering even minor issues, we quickly reached Alert fatigue. Because on paper it seems great to know about all issues – for example, if the application failed to connect to the database on the first attempt and succeeded only after retrying. However, since it has recovered itself, there is no need to generate an Alert notification about such an exceptional occurrence (even during business hours).
But on the other hand, if the problem repeats at least 20 times in 10 minutes, then it may already indicate some issue that would be worth checking. So we've adjusted the notification rules accordingly (in Sentry) and significantly reduced the number of low-priority alerts.
Notification channels
Although we initially rejected email as a notification channel, we only used Slack notifications at first. Whoever had On-Call, took care of the „Alerting“ channel and according to the priority solved the alerts, closed them or created tasks to Backlog. The downside, of course, was that an incoming message to Slack sometimes didn't wake us up at night and wouldn't get delivered without an internet connection.
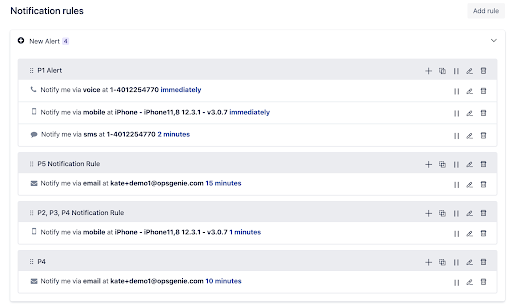
That's why we've also added SMS and voice call notifications in Opsgenie. However, you definitely don't want to get a copy of every Slack alert message in SMS and voice call 🙂 So we modified the notifications as follows:
Slack channel notification immediately
If not ACKed, send an SMS after 5 minutes to the On-Call user
If not ACKed, voice call after 10 minutes to the On-Call user
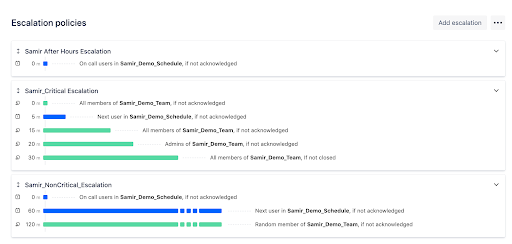
If not ACKed, escalate to the whole team after 90 minutes
We also limited SMS and voice calls to Production priority P1 only. After all, you don't want to be woken up at night by a low-priority bug on stage. It can wait for business hours.
Number of rules
The need for these changes has also shown us that we had too many notification rules. It was tedious to edit all of them and in the end, we actually only need two rules:
Production P1 priority
Slack, SMS and voice call
never closed automatically
24/7, 20 minutes response time
anything else
Slack only
closed automatically after 7 days (because they will be triggered again if the problem persists)
business hours only, response time at a discretion
What if a condition for Production P1 is missing? And some alert is assigned to lower priority? It's just gonna happen (rarely). We'll adjust the conditions, so it doesn't repeat. But in most cases, such missed critical issue triggered another P1 alert anyway (e. g., missed database down → API error budget burnt).
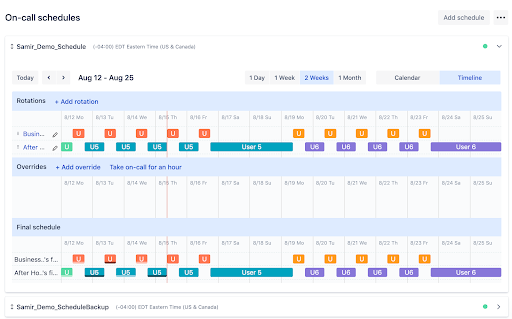
Schedule and rotation
Who is on the On-Call schedule? The whole development team, including the team leader. There were only two of us in the schedule at the beginning and honestly, it's not an ideal number. On average, to be on-call every other night and every other weekend is the path to burnout 😓 Now we are three and rotate seamlessly.
How long is our rotation? Although we have bi-weekly sprints, we rotate after one week. Even the starts are not bound in any way, the rotation change takes place at 7 am on Monday, sprint starts on Thursday. So the next On-Call user starts with a theoretically clean slate and a whole week of time to sort out any issues that might disturb them over the weekend 😉
Although On-Call is only paid for Off hours, we have defined a 24/7 schedule. It's easier, at the end of the month we just sum up the total Off hours for each user in OpsGenie analytics. And we don't have to deal with a bunch of different rules for each day of the week.
Additional responsibilities
Since the On-Call user already has a fragmented day because he has to solve issues and can't focus on bigger tasks anyway, he has to also deal with other things: Attending meetings where a team representative is needed, answering questions on Slack, resolving ad-hoc requests, … So the rest of the team have more time to focus on bigger development tasks.
A „small“ disadvantage is that people outside the team hardly know who currently has On-Call. And who to contact. Opsgenie, unfortunately, doesn't allow you to send a message to the team Slack channel when the rotation is changed. So we've created an internal script that checks every minute if there's been a change in the On-Call schedule and, if so, announces it publicly. Of course, not everyone reads it or notices it, but at least it helps psychologically.
Capacity and Velocity
Formerly, when planning the sprint, we allocated a fixed amount of time for On-Call (and similar) duties. However, sometimes not enough time was reserved, sometimes too much – because it is hard to know in advance how difficult problems will arise.
Therefore, we currently do not set aside any extra On-Call time and let the time spent on on-call tasks gradually affect the velocity of the team.
In conclusion
It is also good to be agile and iterative when setting up On-Calls. Start with a minimum of rules and gradually add more if needed. Also, when designing them, consider whether the problem is really so critical that it needs to be addressed immediately (imagine at the night) and won't wait until business hours.
For sliding/flexible working hours, it is a good idea to utilize the On-Call person for other operational tasks as well. Thus, the rest of the team can focus on more complex work according to their time needs and not have their day scheduled according to various ad-hoc meetings.
The biggest benefit I see in our team is, that On-Calls actually increased effectiveness and responsibility. Except for the colleague in the On-Call rotation, everyone else has a defragmented and focused workday, quiet nights, and free weekends 😉. Similarly, any tasks (problems/questions/meetings) are responded by one particular On-Call person and there is no wasted concurrent work time on the same task by somebody else.








 Follow us on Twitter
Follow us on Twitter
 Follow us on GitHub
Follow us on GitHub