







How are float and list data types represented in Python? Why do they take up so much memory? Why are some operations on them so slow? And why do so many people turn to third-party libraries such as NumPy?
In this two-part article, we take a closer look at the implementation of two Python data types: float and list. We will see that with the flexibility of a dynamically typed language, come drawbacks in the form of added complexity and bigger memory requirements.
It is beneficial, not only for Heureka developers, to be aware of the lower level implementations of functions and data types one uses for it improves the efficiency of the code and also reduces the risk of making errors.
Throughout the post I'll make a few simplifications (e.g. regarding any reusing of objects by the interpreter) to keep it brief. However, there should not be much loss of generality when we think of arbitrarily large lists and random floats. I describe these structures as they are implemented in CPython (specifically CPython 3.10.0).
PyObject: The Basis of All Other Types
Let us start by saying that all data types in Python are objects. There are no primitive types.
On a lower level, every object “inherits” from the PyObject struct. More precisely, because CPython is in C, inheritance is implemented by holding an instance of the predecessor class. This provides an option to cast a pointer to every object to a pointer to PyObject (in C++, a pointer to descendant can be cast to a pointer to predecessor). This casting possibility is an important feature, as we will see later.
The PyObject struct contains a reference counter and a pointer to a type:
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
PyTypeObject *ob_type;
} PyObject;where _PyObject_HEAD_EXTRA is a macro for creating two pointers forming a doubly-linked list of objects for the garbage collector (to be able to handle self-references):
typedef struct {
// Pointer to next object in the list.
// 0 means the object is not tracked
uintptr_t _gc_next;
// Pointer to previous object in the list.
// Lowest two bits are used for flags documented later.
uintptr_t _gc_prev;
} PyGC_Head;These pointers are created for, among others, list, some tuples, some dicts, or user-defined classes, but not for types that can not hold references to themselves (e.g., int, float, . . . ) because those can be collected using a simple reference counter. For more interested readers, here is brilliant documentation of Python’s garbage collector.
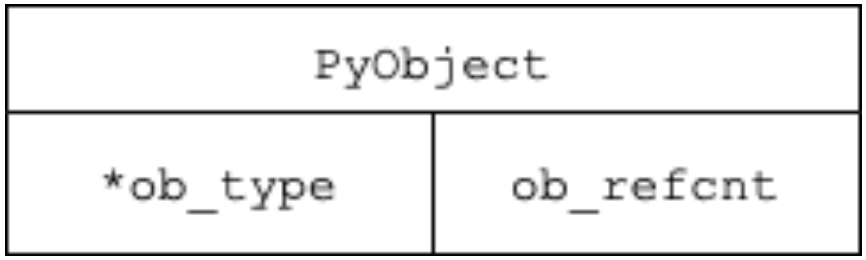
Figure 1: Diagram of memory representation of PyObject
PyFloatObject: Implementation of Float
The float object contains an instance of a PyObject and the value itself, which is actually a C double (64-bit floating-point number) which may be slightly confusing for a developer used to a C-family language.
As a result, a float object uses 24 bytes of memory on a 64-bit system (8B for the pointer to the object type, 8B for the reference counter, and 8B for its value).
The implementation of a PyFloatObject:
typedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObjectwhere PyObject_HEAD is just a macro for creating a PyObject. Let us check the size of a float:
import sys a = 1.0 print(sys.getsizeof(a)) # result: 24

Figure 2: Diagram of memory representation of PyFloatObject
Now, as a preparation for the next part (coming soon) of this article, let’s take a brief look at caches, their role inside a modern computer, and how they speed up commonly used algorithms.
Intermission About Cache
The main memory in a computer is too slow for a common, personal CPU. To speed up computation, modern computers use a faster and smaller memory called cache (or more commonly several differently fast and sized caches). Reading from a cache is about 10-100 times faster than reading from the main memory.
When an address in memory is accessed, the CPU loads a whole block of bytes into the cache (much more than needed, usually). If the required block is already present in the cache, the main memory does not need to be accessed and the computation is faster. If, however, it is not present (so-called cache miss), the CPU needs to load it. This takes time. We want to reduce the number of misses as much as possible.
There are two classes of algorithms that take caches into account: cache-aware and cache-oblivious. Cache-aware algorithms assume or know the parameters of the cache, such as the number of caches, size of the block, number of blocks that fit into a cache,. . . This is often infeasible - most programs run on various hardware. Cache-oblivious algorithms do not know nor assume (almost) anything about caches, they just perform faster when a cache is present.
An example of a simple cache-oblivious algorithm is a sequential scan of an array (general C-like array, not the Python array module): when an element is accessed, a sequence of bytes surrounding the element is cached. When the next element is accessed it is most likely already present in the cache (assuming some common block eviction strategy, like “last-used-evicted-first”). The number of cache misses is minimal (optimal) for a sequential array scan.
On the other hand, scanning a linked list is inefficient with respect to caches. With reading one element and loading a block of surrounding bytes into the cache, no other element in the list is likely to be already present in the cache (assuming the list is arbitrarily long, and cache size is constant). Hence, reading almost every item makes a cache miss.
Hence, if the cache is about n times faster than the main memory, such a scan is about n times faster in an array than it is in a linked list (this is simplified and other factors influence the performance).
For a deeper understanding of cache-oblivious algorithms, see the “Cache” chapter in Data Structures lecture notes by Mareš or Demaine 2002.
Conclusion
In this first part of the article, we have seen the implementation of the base class for all objects in Python, and the implementation of one of its descendants - float.
We have digressed a little bit in the section about cache, but as we will see in the next part (coming soon), which is about list, it is important to know how cache works.
Useful Links and Sources
- https://github.com/python/cpython/blob/main/Include/cpython/float object.h
- https://github.com/python/cpython/blob/main/Include/object.h
- https://github.com/python/cpython/blob/Include/internal/pycore_gc.h
- https://docs.python.org/3/c-api/structures.html
- http://erikdemaine.org/papers/BRICS2002/ - Eric Demaine's paper on cache-oblivious algorithms.
- http://mj.ucw.cz/vyuka/dsnotes/ - Data Structures lecture notes
Author
Ondřej Měkota
Ondřej is a Machine Learning Engineer in Heureka since August 2021. He works on matching product offers from eshops to products in Heureka. He enjoys watching movies, snowboarding, and cooking.
 Follow us on Twitter
Follow us on Twitter
 Follow us on GitHub
Follow us on GitHub