







I attended the International Conference on Learning Representations 2022 as an observer and this article includes a few notes from it.
- 8 talks
- 1095 papers accepted from 3391 submissions
- Most Common Keywords:
- Reinforcement Learning
- Deep Learning
- Representation Learning
- GNNs
- SSL
- Transformer
The International Conference on Learning Representations is an annual machine learning conference. There have been 3391 submissions this year, yielding 1095 papers selected. The most common keywords include reinforcement learning, deep learning, graph neural networks, semi-supervised learning, and transformer. There were 8 invited talks, 55 papers (from those 1095) that had oral presentation, and there were parallel workshops on one of the days.
The conference was virtual this year dues to the coronavirus pandemic as was the case in 2021. Although physical presence is arguably better, the possibility to connect from anywhere makes this a much more accessible event.
Interesting Papers
(A Rather Subjective List)
Understanding over-squashing and bottlenecks on graphs via curvature
The authors address a problem of GNNs on graphs with long-range dependencies where information gets distorted when it flows from distant nodes and it gets compressed to fixed-sized vectors, so called over-squashing. This phenomenon differs from the more studied over-smoothing which is when the fixed-sized vector, to which data from incoming nodes gets compressed is not informative enough – it’s over-smoothed.
They identify which edges are “the most responsible” for over-squashing by introducing Ricci curvature to graphs and showing that the negatively curved edges are causing the over-squashing. By adding new edges, which are ‘similar’ to them (’similar’ means that by adding them, information is able to flow through them more directly during message passing) the over-squashing gets alleviated. Removing edges with maximum Ricci curvature helps in a similar way.
A New Perspective on "How Graph Neural Networks Go Beyond Weisfeiler-Lehman?"
The paper proposes a novel GNN that is more expressive than a 1-WL test (Weisfeiler Lehman test of graph isomorphism) by including local structural information into the message passing.
Using the new generalised message-passing framework, they propose GraphSNN, a new GNN that can overcome the over-smoothing issue and is strictly more expressive than 1-WL test. GraphSNN uses a novel generalised message-passing framework that leverages the structural information of the graph during the aggregation phase. GraphSNN can be used with many common GNN methods, such as GCN, GAT, GraphSAGE, GIN, etc.
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
It is generally known that fine-tuning the whole model performs better than linear probing on an in-distribution dataset. However linear probing performs significantly better than fine-tuning on out-of-distribution datasets.
The authors show both empirically and theoretically that fine-tuning performs worse when the pre-trained features are high quality and the distribution shift is large. This happens because of the randomly initialised final layer, the training of which causes the pre-trained features to be distorted.
A fix is to train the randomly initialised final layer at the beginning with rest of the model fixed, and then fine-tune the whole model when the last layer is good enough.
Pyraformer: Low-Complexity Pyramidal Attention for Long-Range Time Series Modeling and Forecasting
The authors propose an efficient (both in time and space) Transformer architecture by introducing pyramidal attention. Such an approach is especially useful for modelling long range dependencies, as its time complexity per layer is O(N) (N being the length of the sequence) as opposed to O(N^2) in the transformer.
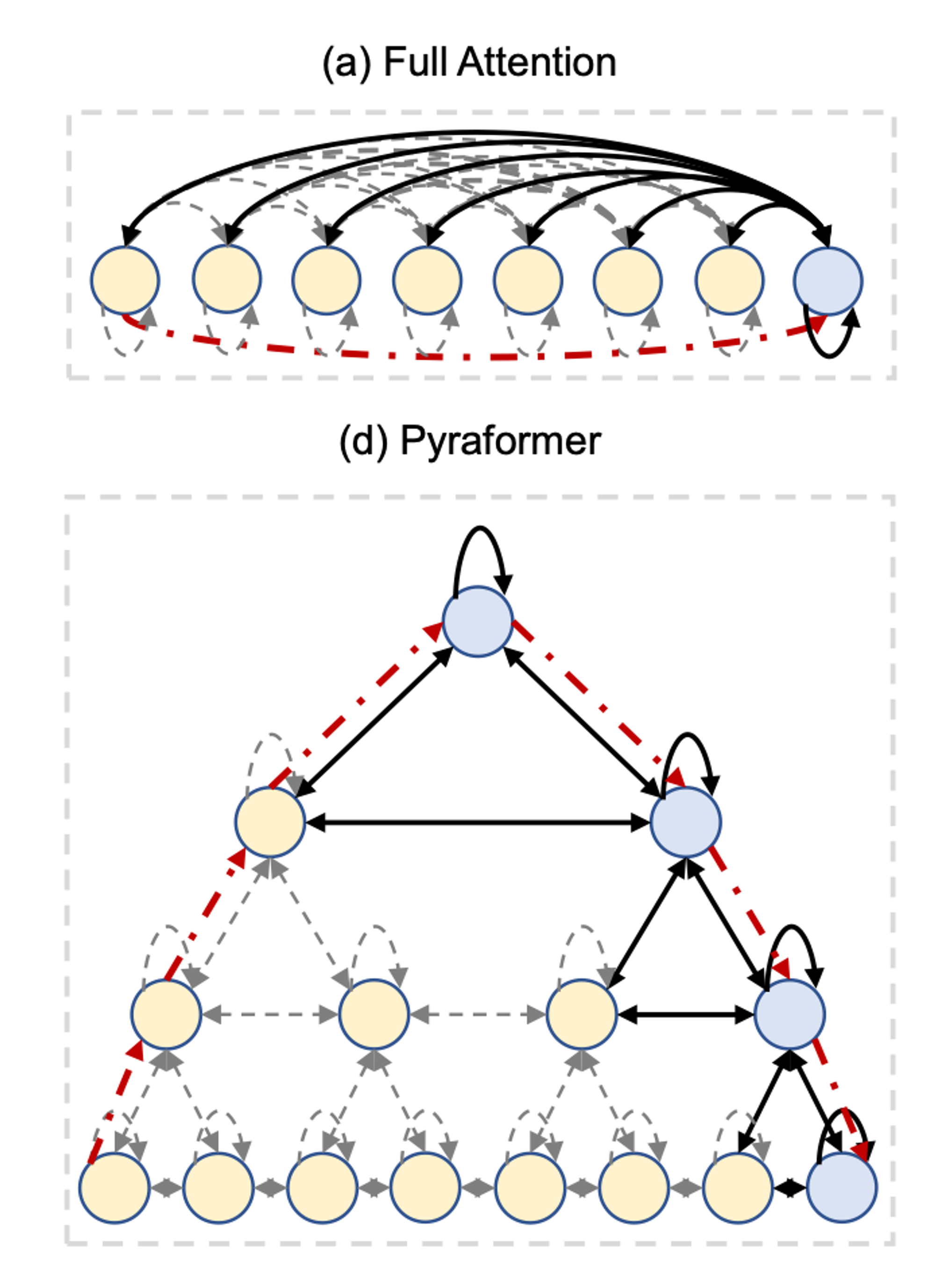
The signal flow chart. The first image is the Transformer, the second the Pyraformer (the nodes at the bottom represent the original input sequence). (Source: The Pyraformer paper)
As we can see in the figure, the original transformer information flow forms a complete graph whereas the information flow in Pyraformer is a pyramid shaped graph; a rooted C-nary tree where nodes on the same level next to each other are connected. Consequently the set of nodes (some of which are latent in the Pyraformer) that are attended to at a given timestamp is significantly smaller, O(1) in Pyraformer compared to O(N) in the Transformer.
Notice that the length of the maximum path that information flows through in Pyraformer (the red, dashed line) is still O(1) (wrt. sequence length).
This novel method is compared to several other transformers (e.g. Longformer or Reformer) on a selection of time series forecasting tasks, outperforming them all.
Author
Ondřej Měkota
Ondřej is a Machine Learning Engineer in Heureka since August 2021. He works on matching product offers from eshops to products in Heureka. He enjoys watching movies, snowboarding, and cooking.
 Follow us on Twitter
Follow us on Twitter
 Follow us on GitHub
Follow us on GitHub