







How to Kill a Monolith Without Killing Yourself – The Strangler Fig Pattern in Practice
Marek Kužel
Every developer dreams of building perfect, flexible systems from scratch. But what happens when you inherit a sprawling monolith that's become a bottleneck for innovation? Rewriting it completely is a huge gamble. At Heureka, we've learned there's a smarter, safer way to modernize complex systems without the "Big Bang" risks: the Strangler Fig pattern. Discover how this powerful architectural approach can help you gradually transform your legacy code, keep your systems running smoothly, and avoid the common pitfalls of large-scale refactoring.
Strangler Fig sounds like a simple pattern.
Wrap the old system, build a new one around it, slowly shift traffic, and once everything works – delete the legacy. Done, right?
Reality check:
- The old system still „kind of works“.
- The new one is „almost ready“.
- And someone from Product wants an A/B test. Just in case.
If you've never heard of the Strangler Fig pattern: it's a way to replace legacy code gradually and safely – without downtime, and without betting everything on a Big Bang rewrite.
The name comes from Martin Fowler, who needed something more exciting than „incremental modular replacement“ for his consulting slides. So he borrowed the image of a tropical vine that slowly grows around a tree, eventually replacing it completely.
It’s an elegant idea.
But like most elegant ideas, the pain is in the execution.
What’s the Point of This Pattern?
Strangler Fig is useful when:
- You can’t afford downtime
- The system is too big or risky to rewrite at once
- You want to evolve architecture while keeping the lights on
It works by introducing a layer of indirection – a proxy, API, or routing logic – that decides whether to use the old or new implementation.
Over time, more traffic goes to the new part. Eventually, you remove the old one entirely.
Example from Microsoft – In Human Terms
In one Microsoft example, the legacy system writes to a database.
Let’s say you want to replace it with a new system – without breaking everything.
Instead of rewriting all at once, you:
- Introduce a new database alongside the old one.
- Start double writing to both databases:
- Either directly in the application (simple but tightly coupled),
- Or by streaming changes (e. g. using CDC) from the old system to the new one – like Amazon does.
- Adjust reads to prefer the new database when data is available.
- Backfill historical data, or let it naturally phase out.
- Once confident: stop writing to the legacy DB, route all reads to the new one, and delete the old system.
The double-write phase is critical – it's where bugs hide, metrics skew, and someone inevitably says:
“Wait, why do we have three different numbers for revenue?”
But it’s the bridge that makes safe migration possible.
Visual Example:
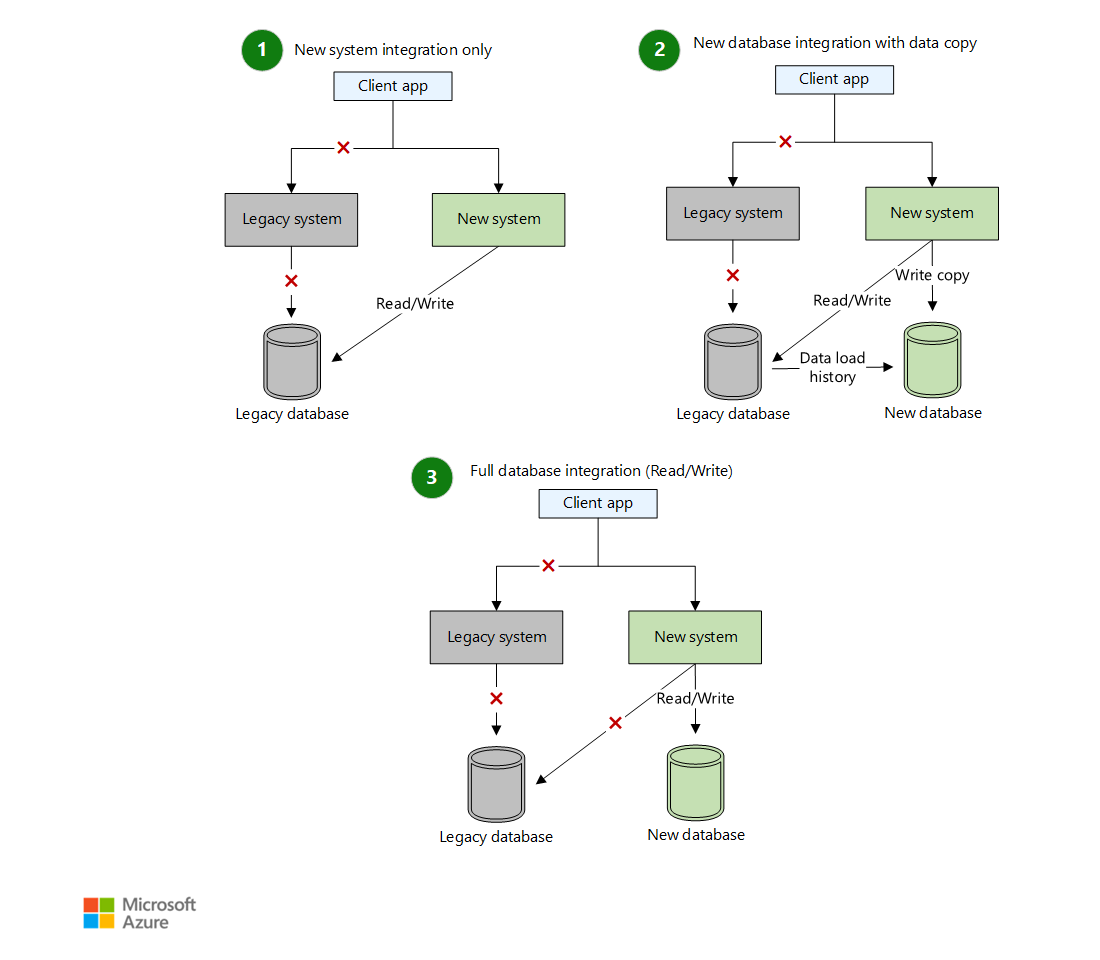
https://learn.microsoft.com/en-us/azure/architecture/patterns/strangler-fig
Why Bother?
- Deploy incrementally and test quickly
- Reduce risk and blast radius
- Upgrade critical logic with zero downtime
- Avoid the mythical Big Bang rewrite
Prerequisites (Why Most Teams Fail)
To pull this off, you need:
- A clear entry point you can intercept (API, proxy, message bus, etc.).
- Monitoring and observability – logs, metrics, alerts. If something fails during routing or dual writes, you want to know now, not when someone posts it in Slack.
- Feature toggles or routing logic to control rollout gradually.
- Clear ownership and cleanup process – someone has to decide when legacy can be deleted, and actually do it.
- A team that can handle ambiguity and incomplete boundaries (Strangler Fig projects rarely start with perfect specs).
This is as much about process and discipline as it is about code.
Where Can You Use It?
Anywhere you can flip a switch:
- Frontend → backend: redirect UI calls behind the scenes
- API → DB: keep the same contract, swap the data layer
- Batch → event-based: replace cron jobs with streams
- Service → service: replace internals behind a stable interface
It’s a pattern, not a tech stack.
What Can Go Wrong?
- You end up with two systems forever – no one dares remove the old one.
- You create proxy hell – unreadable routing logic with „just one more flag“.
- You introduce data inconsistencies between old and new sources.
- Monitoring blind spots – issues go undetected.
- You never clean up – technical debt just migrates, it doesn’t disappear.
- A half-finished Strangler Fig becomes a Frankenstein – not an improvement.
Don’t half-strangle. Kill cleanly, or don’t bother.
Real-Life Example: Heureka's Index Swap
At Heureka, we actually got this pattern right. Here’s what we did:
- We had a Search API powered by an Elasticsearch index filled by our legacy monolith.
- We built a new indexing pipeline consuming Entities.
- We turned the Search API into a proxy, routing some queries to the new index.
- After verifying results, we deleted the old index and stopped feeding it.
No Big Bang, no drama – just gradual routing, testing, and cleanup. This was Strangler Fig applied not at the UI/API layer, but deep in the data pipeline.
And yes – we actually deleted the legacy code. That alone is a win.
Author
Marek Kužel
Marek is part of staff engineering team, focused on finding the best tools and ways to connect different parts of the system so everything runs smoothly, even when things get complicated.
 Follow us on Twitter
Follow us on Twitter
 Follow us on GitHub
Follow us on GitHub